Рано или поздно возникает вопрос — что мешает делать размытие, ресамплинг или любой другой алгоритм обработки изображения сразу для всех экосистем? Решения из коробки в Delphi нет. Существующие сторонние решения слишком громоздки и навсегда привязывают к себе. Давайте сделаем лёгкий интерфейс, который будет одинаково восприниматься и в VCL, и в FMX, и в Lazarus.
Причины
Алгоритмы обработки изображения — это по сути не самая сложная математика, которая что-то делает с пикселями, иногда в зависимости от состояния соседей. Математика — абстракция по природе, и как-то очень не хочется прибивать её гвоздями к одному фреймворку. Отпустить её на простор кроссплатформенности по сути ничего не стоит, она изначально абстракция.
Обработка изображения часто представляет собой некую функцию, принимающую параметром TBitmap. Если работаем в VCL, это будет Vcl.Graphics.TBitmap, если в FMX — это FMX.Graphics.TBitmap. А это совершенно разные типы, имеющие разный набор методов, построенных от разных родителей. Они связаны только семантически — прямоугольный набор пикселей, и всё, больше ничего общего.
В трёх статьях про blur (1, 2, 3) мы методично оптимизировали размытие: от 1593 мс до 15 мс. Алгоритмы получились хорошие, быстрые. Но все они жёстко привязаны к TBitmap из VCL. Хотя сама математика: скользящая сумма, треугольное ядро, свёртки, не имеет никакого отношения к VCL. Ей всё равно, кто предоставит байты пикселей.
Хотелось бы в итоге получить способ, позволяющий вместо TBitmap использовать нечто такое, что без проблем скомпилируется во всех трёх экосистемах, не теряя производительности и скорости алгоритма. Но при этом, чтобы сам битмап был в рамках своей экосистемы.
В этой статье мы спроектируем интерфейс IImageSurface32, тонкую прослойку, которая отделит наши алгоритмы от фреймворка. Один и тот же код обработки пикселей должен одинаково работать поверх Vcl.Graphics.TBitmap, FMX.Graphics.TBitmap и TLazIntfImage.
Формальные требования
Почему именно интерфейс, а не класс? Во-первых, алгоритму обработки изображений не надо знать ничего про класс — просто дай мне пиксели, я с ними что-то сделаю и отдам обратно. Во-вторых, все перечисленные в заголовке экосистемы прекрасно понимают интерфейс. В-третьих, реализуя конкретный интерфейс, я могу поступать как удобней — может, сделаю оболочку над специфичным Bitmap, а может, буду сам хранить данные.
И в-четвёртых — самое главное. В статьях «Прямой доступ к пикселям Bitmap» и «TBitmap.ScanLine: Полное руководство» подробно показано: для быстрой обработки изображения нужны всего две вещи — указатель на байты массива пикселей и ширина строки в байтах. Не «удобный API», не «правильный класс». Указатель и stride. Это ядро. Метаданные — ширина, высота, альфа-режим — обвязка вокруг ядра, разберём ниже.
А почему не GR32?
Graphics32 — отличная библиотека. Я сам её много раз использовал, упоминал с уважением в статьях. Библиотека десятилетиями полирует свои алгоритмы. Но есть архитектурное различие, из-за которого она не годится в качестве основы для нашей прослойки.
Вежливое оппонирование невидимому собеседнику спрячу в спойлер, к статье не имеет никакого отношения.
Это разные ниши. Graphics32 — дом для растровых данных. IImageSurface32 — это тонкий переходник к уже существующим битмапам. Он не претендует на роль фреймворка, не предлагает свои Canvas, слои, контролы. Он предлагает одну функцию: дать алгоритму указатель на чужие пиксели.
Graphics32 — это десятки модулей, тысячи строк, лицензия LGPL/MPL. IImageSurface32 — это около 50 строк на интерфейс, плюс по сотне строк на каждую реализацию. Минимум кода, минимум зависимостей, нулевой порог вхождения.
Если буду использовать TBitmap32 в качестве параметра для своих алгоритмов, то во-первых, придётся протаскивать и модули GR32, что снова прибивает математику гвоздями к чужому фреймворку — только теперь к Graphics32 вместо VCL. Во-вторых, навечно привяжу себя к сторонней библиотеке, в которой однажды может что-то измениться или сломаться без меня. В-третьих, мне совершенно не нужна вся мощь библиотеки, мне просто нужен универсальный мостик, который находится в одном модуле. Который можно прочитать за чашку кофе — и понять полностью.
Проще говоря, GR32 — это фреймворк. Ниша нашего интерфейса — переходник между фреймворком и экосистемой. Это не замена фреймворка, а коммуникация с ним.
Чтобы работать с алгоритмами обработки изображения, не надо предварительно изучать фреймворк, надо заниматься исключительно алгоритмами.
Список требований к интерфейсу
— Лёгкость. Прочитать и понять код полностью за один заход. Не неделю.
— Минимум модулей. Один интерфейс. Несколько лёгких реализаций. Без иерархий, без обвязки, без «архитектурного жирка».
— Никаких внешних зависимостей. Только то, что уже есть в Delphi. Никаких DLL, никаких лицензий, никаких дополнительных скачиваний библиотек и компонент.
— Нулевой оверхед. Прослойка должна быть бесплатной по производительности. Виртуальный вызов на старте обработки строки — да, виртуальный вызов на каждый пиксель — нет.
Одним словом, должно получиться нечто лёгкое, понятное и, одновременно, универсальное. Чтобы можно было писать свои реализации почти копипастом.
Интерфейс IImageSurface32
Предлагается такой интерфейс:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
// Поверхность 32-битных BGRA пикселей IImageSurface32 = interface ['{0FB211FD-B255-43BB-90EB-95312DD40C40}'] function GetWidth: Integer; function GetHeight: Integer; function GetScanLine(Y: Integer): PPixel32Array; function GetAlphaMode: TAlphaMode; function GetData: Pointer; procedure SetAlphaMode(const Value: TAlphaMode); // Установить размеры procedure SetSize(AWidth, AHeight: Integer); // Создать новый экземпляр function CreateSurface: IImageSurface32; property Width: Integer read GetWidth; property Height: Integer read GetHeight; // Начало массива пикселей: // Возвращает указатель на начало непрерывного блока // пикселей в памяти, откуда можно последовательно // читать всю поверхность по пикселям. // Порядок строк (например, bottom-up или top-down) - // не фиксируется и зависит от реализации. property Data: Pointer read GetData; // Строка по индексу Y, отсчёт от верха property ScanLine[Y: Integer]: PPixel32Array read GetScanLine; default; // Текущий альфа-режим property AlphaMode: TAlphaMode read GetAlphaMode write SetAlphaMode; end; |
И всё? Ага, лёгкий, самодостаточный, только необходимое. Используемые типы:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
type // Внутренний формат пикселя // Жёстко фиксирован на 32-битный BGRA TPixel32 = packed record B: Byte; G: Byte; R: Byte; A: Byte; class operator Equal(const A, B: TPixel32) : Boolean; class operator NotEqual(const A, B: TPixel32): Boolean; class operator Add(const A, B: TPixel32): TPixel32; class function Zero: TPixel32; static; function Invert: TPixel32; function Lighter(Value: Byte): TPixel32; function Darker(Value: Byte): TPixel32; end; PPixel32 = ^TPixel32; TPixel32Array = array[0..0] of TPixel32; PPixel32Array = ^TPixel32Array; // Кэш ScanLine - чтобы не вызывать ScanLine[Y] повторно TScanLineCache = array of PPixel32Array; // Интерпретация альфа-канала TAlphaMode = ( amIgnored, // альфа не участвует в алгоритмах amPremultiplied // цвета предумножены на альфу ); |
Собственно, тоже ничего сверхъестественного. Зафиксируем, что работать собираемся только с 32-битным пикселем. Это и быстрее, и универсальнее. Альфу мы любим, помним, активно используем.
Теперь подробно о том, почему такие решения.
BGRA: Почему такой порядок байт
Почему BGRA, а не RGBA? Это наследие Windows: и в DIB, и в Vcl.Graphics.TBitmap байты в памяти лежат именно в порядке B, G, R, A. FMX в Windows-сборке использует тот же порядок.
Для других платформ (macOS, iOS, Android) порядок может быть иной, часто RGBA. В этом случае реализация анализирует исходный порядок и при необходимости формирует BGRA-представление. Но это дело реализации, не алгоритма.
Поэтому BGRA — это выбор, покрывающий большинство задач.
Stride: Почему его нет
Явного Stride в интерфейсе нет. Он всегда равен Width * SizeOf(TPixel32) — то есть строки лежат вплотную, без выравнивания. Это архитектурное обязательство интерфейса: каждая реализация обязана держать пиксели в непрерывном блоке без зазоров. Если приходит битмап, в котором это не так, то реализация должна скопировать пиксели в свой буфер. Обязательство непрерывности буфера упрощает алгоритмам жизнь: можно пробежать всю поверхность одним линейным циклом по Data, без построчных переходов.
Data: Инструмент скоростной обработки
В комментарии читаем, что порядок строк у нас нигде не хранится. То есть мы не знаем, строки идут снизу вверх или сверху вниз. Зачем тогда нам Data?
Data — это специализированный инструмент для попиксельных операций, в которых порядок обхода не важен — вроде premultiply, gamma correction, color matrix, threshold. Для алгоритмов, где нужны соседи (свёртки, blur, edge detection), надо использовать ScanLine[Y]. Реализация не обязана располагать строки сверху вниз: VCL держит их снизу вверх, FMX — сверху вниз, и Data указывает на начало этого блока в его естественном порядке.
Реальный пример использования Data будут в конце статьи, сейчас зафиксируем два шаблона — для случая, когда порядок строк не важен, и когда важен.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
// Pattern 1: попиксельно, порядок не важен — через Data Total := Surface.Width * Surface.Height; S := PPixel32(Surface.Data); for I := 0 to Total - 1 do begin // ... работа с S^ Inc(S); end; // Pattern 2: построчно, с соседями — через ScanLine for Y := 0 to Surface.Height - 1 do begin Row := Surface[Y]; for X := 0 to Surface.Width - 1 do begin // ... работа с Row[X] end; end; |
AlphaMode: Два режима, не три
Почему два режима, а не три? В классической графической литературе обычно различают три состояния альфы: ignored, straight (она же unassociated), premultiplied. Я свёл их к двум, и вот почему.
В VCL есть три значения AlphaFormat: afIgnored, afDefined, afPremultiplied. На первый взгляд — три режима. Но если посмотреть в VCL изнутри: при присвоении afDefined или afPremultiplied битмапу, в котором уже есть данные, вызывается внутренняя PreMultiplyAlpha, которая физически домножает каналы на альфу. При обратном переходе на afIgnored внутренняя UnPreMultiplyAlpha делит обратно. А вот между afDefined и afPremultiplied никакого преобразования нет — разница между ними чисто семантическая, «пометка для GDI».
То есть в VCL фактически два физических состояния пикселей: либо они premultiplied, либо нет. Третьего не существует. Подробнее я это описал в статье про особенности блюра с альфа-каналом.
В FMX битмап всегда premultiplied — режима нет, выбора нет.
В LCL пиксели всегда в straight-форме — режима тоже нет, premultiply делает приложение.
Получается: на трёх платформах три разных дефолта, но физических состояний только два: умножено или нет. Поэтому в IImageSurface32 я закрепляю именно физический смысл: amIgnored означает «альфа не используется алгоритмами, последний байт можно считать мусором», amPremultiplied — «RGB уже умножены на A, алгоритмы это учитывают». Третьего режима нет, потому что в железе его и не было.
Width и Height: Простые свойства
Простые информационные свойства — ширина и высота поверхности в пикселях. Без них не обходится ни один алгоритм обработки изображений. Доступны только по чтению. Чтобы их изменить, следует вызвать SetSize.
CreateSurface: Фабрика
Этот метод создаёт новый экземпляр той же реализации, что и текущий. Это нужно алгоритмам, которым требуется временный буфер или место для результата: алгоритм размытия не должен знать, в какой экосистеме он работает (VCL, FMX, LCL), он просто говорит «дай мне такую же поверхность» и получает её. Отдельная фабрика для этого избыточна, мы не хотим плодить интерфейсы, когда задача решается одним методом.
SetSize: Установка размеров битмапа
Устанавливает новые размеры битмапу, обёрнутому интерфейсом. На практике метод почти всегда идет в паре с CreateSurface: создал экземпляр того же типа, и тут же задал размер:
|
1 2 |
Tmp := Source.CreateSurface; Tmp.SetSize(Source.Width, Source.Height); |
Сразу же реализуем интерфейс, который хранит данные пикселей в собственном внутреннем буфере.
Реализация интерфейса: TMemoryImageSurface32
Это первая реализация интерфейса IImageSurface32. Она не зависит от платформы и владеет собственным буфером пикселей в памяти. Полезна в сценариях, где нужен временный рабочий буфер для промежуточных данных алгоритма, когда возвращается новая поверхность в качестве результата, а также как место для конвертации из чужих форматов с другим порядком байт.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
// In-memory implementation / Реализация в памяти TMemoryImageSurface32 = class(TInterfacedObject, IImageSurface32) strict protected FWidth: Integer; FHeight: Integer; FStride: Integer; // = FWidth * SizeOf(TPixel32), кэш для GetScanLine FData: TBytes; FAlphaMode: TAlphaMode; function GetWidth: Integer; inline; function GetHeight: Integer; inline; function GetAlphaMode: TAlphaMode; inline; procedure SetAlphaMode(const Value: TAlphaMode); inline; function GetData: Pointer; inline; procedure CheckRange(Y: Cardinal); inline; // Virtual block function GetScanLine(Y: Integer): PPixel32Array; virtual; function CreateSurface: IImageSurface32; virtual; public constructor Create; overload; constructor Create(AWidth, AHeight: Integer); overload; procedure SetSize(AWidth, AHeight: Integer); property Width: Integer read GetWidth; property Height: Integer read GetHeight; property AlphaMode: TAlphaMode read GetAlphaMode write SetAlphaMode; property Data: Pointer read GetData; property ScanLine[Y: Integer]: PPixel32Array read GetScanLine; default; end; |
И реализация:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
{ TMemoryImageSurface32 } constructor TMemoryImageSurface32.Create; begin inherited Create; FAlphaMode := amIgnored; end; constructor TMemoryImageSurface32.Create(AWidth, AHeight: Integer); begin Create; // делегируем, там будет вызов inherited SetSize(AWidth, AHeight); end; procedure TMemoryImageSurface32.SetSize(AWidth, AHeight: Integer); var ByteCount: NativeInt; begin if (AWidth < 0) or (AHeight < 0) then raise EArgumentException.Create('SetSize: Dimensions cannot be negative'); FWidth := AWidth; FHeight := AHeight; FStride := FWidth * SizeOf(TPixel32); ByteCount := NativeInt(FHeight) * NativeInt(FStride); if (FHeight <> 0) and (ByteCount div NativeInt(FHeight) <> NativeInt(FStride)) then raise EIntOverflow.Create('SetSize: buffer size overflow'); SetLength(FData, ByteCount); end; function TMemoryImageSurface32.GetWidth: Integer; begin Result := FWidth; end; function TMemoryImageSurface32.GetHeight: Integer; begin Result := FHeight; end; function TMemoryImageSurface32.GetAlphaMode: TAlphaMode; begin Result := FAlphaMode; end; procedure TMemoryImageSurface32.SetAlphaMode(const Value: TAlphaMode); begin FAlphaMode := Value; end; procedure TMemoryImageSurface32.CheckRange(Y: Cardinal); begin if Y >= Cardinal(FHeight) then raise ERangeError.CreateFmt('ScanLine index out of range: %d', [Y]); end; function TMemoryImageSurface32.GetScanLine(Y: Integer): PPixel32Array; begin CheckRange(Cardinal(Y)); Result := PPixel32Array(@FData[NativeInt(Y) * FStride]); end; function TMemoryImageSurface32.GetData: Pointer; begin Result := Pointer(FData) end; function TMemoryImageSurface32.CreateSurface: IImageSurface32; begin Result := TMemoryImageSurface32.Create; end; |
Несколько комментариев по реализации.
Паттерн использования
Конструкторов два — без параметров и с размерами. Может показаться, что параметризованный удобнее: создал и сразу получил поверхность нужного размера. Но в реальной работе с битмапами часто нужен другой порядок:
|
1 2 3 |
Surface := TMemoryImageSurface32.Create; Surface.AlphaMode := amPremultiplied; Surface.SetSize(W, H); |
Сначала создаём пустой объект, затем выставляем альфа-режим, и только потом — размер. Почему именно так?
Дело в том, что в реализациях поверх реальных битмапов, например, Vcl.Graphics.TBitmap, присваивание AlphaFormat после того, как размер уже задан, физически перебирает все пиксели и применяет к ним premultiply либо unpremultiply. Если это сделать на пустом, но большом буфере — получим лишний длительный проход, совершенно бессмысленный, потому что происходит на нулях. Подробнее чуть ниже, в VCL-реализации.
Установив сначала режим альфы (на пустом нулевом объекте), потом размер, мы избегаем этой работы: преобразовывать нечего, а после SetSize буфер уже считается находящимся в нужном состоянии.
Для TMemoryImageSurface32 этой проблемы нет — у нас SetAlphaMode просто меняет поле без обработки данных. Но паттерн должен быть единым для всех реализаций интерфейса. Поэтому делать его привычным имеет смысл с самой первой, простейшей реализации.
CreateSurface создаёт пустой экземпляр
|
1 2 3 4 |
function TMemoryImageSurface32.CreateSurface: IImageSurface32; begin Result := TMemoryImageSurface32.Create; end; |
Никаких размеров, никаких унаследованных свойств. Можно было бы сделать так, чтобы новая поверхность приходила сразу того же размера и с той же альфой, что и текущая. Но это означало бы додумывать действия программиста: а вдруг ему нужна поверхность другого размера? А вдруг с другой альфой? Поэтому лучше всегда следовать паттерну Create -> AlphaMode -> SetSize явно, по своим задачам, а не заниматься предсказаниями.
SetSize не сбрасывает AlphaMode
AlphaMode — это семантическая пометка, описывающая, как алгоритмы должны интерпретировать пиксели. Она не привязана к содержимому буфера: установили amPremultiplied, потом перевыделили буфер через SetSize — пометка осталась прежней. Новый буфер обнулён, нули формально удовлетворяют premultiplied-семантике (0 умножен на любую альфу = 0), так что сохранение режима корректно.
Это сознательное решение: режим альфы — свойство поверхности, а не содержимого. Программист берёт на себя наполнение буфера правильными данными, соответствующими заданному режиму.
Реальную прослойку, не хранящую пиксели, удалось сделать только для VCL. Но давайте по порядку, для каждой экосистемы. И начнём с LCL.
Реализация для LCL
LCL — экосистема, где прямой доступ к буферу битмапа невозможен. TBitmap в LCL общается с GDI/GTK/Qt/Cocoa через handle, а пиксели достаёт через посредника — TLazIntfImage. Поэтому делаем реализацию, копирующую данные в свой внутренний буфер. Это значит, что пишем наследника от TMemoryImageSurface32:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
type // Поверхность в памяти с копированием в/из TBitmap TLclMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; public constructor CreateFromBitmap(const ABitmap: TBitmap); constructor CreateFromGraphic(AGraphic: TGraphic); procedure CopyFromBitmap(const ABitmap: TBitmap); procedure CopyFromGraphic(AGraphic: TGraphic); procedure CopyToBitmap(var ABitmap: TBitmap); end; |
Класс наследуется от TMemoryImageSurface32 и ничего в нём не переопределяет, кроме CreateSurface. Не нужен переопределённый GetScanLine, не нужен свой GetData, не нужен какой-то особый порядок строк. Всё, что у него своё — это способ обмена с LCL-битмапом.
Добавляем пару конструкторов и пару методов обмена с битмапом. Вся специфика платформы локализована в CopyFromBitmap и CopyToBitmap.
Один нюанс: TGraphic вместо TBitmap
В LCL TBitmap — это конкретно растровый битмап, а PNG, JPEG и прочие живут как отдельные классы-потомки TGraphic. И когда нужно загрузить, скажем, PNG, приходится сначала превратить его в TBitmap, а уже потом разбираться с пикселями.
Логичная попытка Bitmap.Assign(PngImage) работает не всегда: для некоторых форматов и виджет-сетов handle остаётся не материализованным до первой реальной отрисовки, и LoadFromBitmap потом возвращает пустоту. Поэтому в библиотеке есть отдельная свободная функция-помощник:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
// Материализует произвольный TGraphic (PNG/JPEG/BMP/...) // в 32-битный TBitmap с валидным читаемым handle. // Возвращает новый TBitmap, владение — у вызывающего function GraphicToBitmap32(AGraphic: TGraphic): TBitmap; begin Result := TBitmap.Create; Result.PixelFormat := pf32bit; try if (AGraphic = nil) or (AGraphic.Width = 0) or (AGraphic.Height = 0) then Exit; Result.SetSize(AGraphic.Width, AGraphic.Height); // Canvas.Draw надёжно растрирует любой TGraphic в наш 32-битный битмап, // в отличие от Assign, который для PNG/JPEG может оставить handle "пустым" Result.Canvas.Draw(0, 0, AGraphic); except FreeAndNil(Result); raise; end; end; |
Canvas.Draw гарантированно растрирует любой TGraphic в наш 32-битный битмап с гарантированно валидным handle. Это «на всякий случай надёжный» путь, специально для LCL.
Применение:
|
1 2 3 4 5 6 7 8 9 10 11 |
procedure TLclMemorySurface32.CopyFromGraphic(AGraphic: TGraphic); var Tmp: TBitmap; begin Tmp := GraphicToBitmap32(AGraphic); try CopyFromBitmap(Tmp); finally Tmp.Free; end; end; |
CopyFromBitmap
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
procedure TLclMemorySurface32.CopyFromBitmap(const ABitmap: TBitmap); var IntfImg: TLazIntfImage; Desc: TRawImageDescription; Y: Integer; SrcPtr, DstPtr: PByte; RowSize: Integer; begin if ABitmap = nil then raise Exception.Create('CopyFromBitmap: ABitmap must not be nil'); Desc.Init_BPP32_B8G8R8A8_BIO_TTB(ABitmap.Width, ABitmap.Height); IntfImg := TLazIntfImage.Create(0, 0); try IntfImg.DataDescription := Desc; IntfImg.LoadFromBitmap(ABitmap.Handle, ABitmap.MaskHandle); SetSize(IntfImg.Width, IntfImg.Height); FAlphaMode := amIgnored; RowSize := FWidth * SizeOf(TPixel32); for Y := 0 to FHeight - 1 do begin SrcPtr := PByte(IntfImg.GetDataLineStart(Y)); DstPtr := @FData[NativeInt(Y) * FStride]; Move(SrcPtr^, DstPtr^, RowSize); end; finally IntfImg.Free; end; end; |
Здесь работает важный приём — явное задание формата через Init_BPP32_B8G8R8A8_BIO_TTB. Эта строчка говорит LCL: «я хочу 32-битные пиксели, в порядке BGRA, с расположением строк сверху вниз». Дальше LoadFromBitmap сам выполнит любую необходимую конверсию из внутреннего формата платформенного битмапа в наш желаемый формат.
Здесь мы не выясняем, как у нас на самом деле лежат байты в TBitmap, мы просто говорим LCL, как мы хотим их получить, и платформа сама приводит к этому виду. В итоге один Move на всю строку — и всё.
Цена этой простоты — мы платим временем LoadFromBitmap внутри LCL, который и делает реальную конверсию, если она нужна. Но это всё равно один проход по данным, и он уже оптимизирован в недрах LCL.
FAlphaMode := amIgnored — сознательное решение. LCL не предоставляет ни одного достоверного способа выяснить, premultiplied данные в битмапе или straight. Виджет-сет может прислать любое — в зависимости от платформы, от того, откуда взялся битмап, и от фазы луны. Поэтому консервативная позиция: считаем, что альфы нет, обрабатываем поверхность как непрозрачную. Если пользователь точно знает, что у него premultiplied PNG — он может выставить режим вручную после копирования.
CopyToBitmap
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
procedure TLclMemorySurface32.CopyToBitmap(var ABitmap: TBitmap); var IntfImg: TLazIntfImage; Desc: TRawImageDescription; Y: Integer; SrcPtr, DstPtr: PByte; RowSize: Integer; ImgH, MskH: HBITMAP; begin if ABitmap = nil then ABitmap := TBitmap.Create; ABitmap.PixelFormat := pf32bit; ABitmap.SetSize(FWidth, FHeight); Desc.Init_BPP32_B8G8R8A8_BIO_TTB(FWidth, FHeight); IntfImg := TLazIntfImage.Create(0, 0); try IntfImg.DataDescription := Desc; IntfImg.SetSize(FWidth, FHeight); RowSize := FWidth * SizeOf(TPixel32); for Y := 0 to FHeight - 1 do begin SrcPtr := @FData[NativeInt(Y) * FStride]; DstPtr := PByte(IntfImg.GetDataLineStart(Y)); Move(SrcPtr^, DstPtr^, RowSize); end; IntfImg.CreateBitmaps(ImgH, MskH, False); ABitmap.Handle := ImgH; ABitmap.MaskHandle := MskH; finally IntfImg.Free; end; end; |
Зеркальный метод, но с одной важной особенностью, специфичной для LCL: выгрузка в битмап делается через подмену handle. Мы сначала складываем пиксели в TLazIntfImage, потом просим у него свежий HBITMAP через CreateBitmaps, и подставляем его в TBitmap.
Это значит: handle целевого битмапа после CopyToBitmap — другой, не тот, что был до вызова. Если у пользователя где-то сохранён старый handle (например, он передал его в нативный API или закэшировал) — этот handle становится невалидным.
В практике обычной обработки изображений это никого не задевает: сохранил битмап, потом его нарисовал, потом забыл. Но если кто-то строит более сложные сценарии с передачей handle наружу — стоит помнить. Это вынужденная особенность LCL: записать пиксели в существующий handle средствами TLazIntfImage нельзя, можно только пересоздать.
Итог по LCL
Вся специфика LCL уместилась в:
- одну вспомогательную функцию растеризации (GraphicToBitmap32);
- два метода обмена с битмапом (CopyFromBitmap / CopyToBitmap);
- два конструктора-загрузчика для удобства.
Есть одна особенность, о которой стоит помнить: CopyToBitmap пересоздаёт handle. На стандартных сценариях обработки изображений это незаметно, но в нестандартных может стать сюрпризом.
По строкам кода — меньше, чем идущий следом FMX. Главная экономия — в отсутствии ручного свопа каналов: TLazIntfImage берёт всю эту работу на себя, нам остаётся только сказать ему желаемый формат через Init_BPP32_B8G8R8A8_BIO_TTB.
Переходим к реализации в FMX, в котором обещаны какие-то дополнительные действия с пискселями.
Реализация для FMX
В FMX, аналогично LCL, мы не имеем прямого доступа к буферу битмапа, пиксели можно получить только через короткоживущий Map, и удерживать его на время работы алгоритма нельзя. Плюс на iOS/macOS/Android внутренний порядок каналов может быть RGBA, а наш интерфейс требует BGRA. Поэтому здесь также только одна реализация, аналог TLclMemorySurface32.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
type // Поверхность в памяти с копированием в/из FMX TBitmap TFmxMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; public constructor CreateFromBitmap(const ABitmap: FMX.Graphics.TBitmap); constructor CreateFromFile(const AFileName: string); constructor CreateFromStream(AStream: TStream); procedure CopyFromBitmap(const ABitmap: FMX.Graphics.TBitmap); procedure CopyFromFile(const AFileName: string); procedure CopyFromStream(AStream: TStream); procedure CopyToBitmap(var ABitmap: FMX.Graphics.TBitmap); end; |
Вся специфика FMX полностью локализована в двух методах — CopyFromBitmap и CopyToBitmap. Остальное унаследовано.
Конструкторы и фабрика
Конструкторов три — для трёх типичных источников: готовый TBitmap, файл, поток. Все они тонкие: вызывают базовый Create и затем соответствующий CopyFrom…:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
constructor TFmxMemorySurface32.CreateFromBitmap( const ABitmap: FMX.Graphics.TBitmap); begin inherited Create; CopyFromBitmap(ABitmap); end; constructor TFmxMemorySurface32.CreateFromFile( const AFileName: string); begin inherited Create; CopyFromFile(AFileName); end; constructor TFmxMemorySurface32.CreateFromStream(AStream: TStream); begin inherited Create; CopyFromStream(AStream); end; |
CreateSurface — обязательный метод фабрики из интерфейса. Создаёт пустой экземпляр того же типа:
|
1 2 3 4 |
function TFmxMemorySurface32.CreateSurface: IImageSurface32; begin Result := TFmxMemorySurface32.Create; end; |
Главный нюанс: порядок каналов
Вся специфика FMX сводится к одному решению: как лежат байты в памяти. На Windows FMX использует BGRA — наш родной формат, копировать можно Move. На iOS, macOS и Android может использоваться RGBA, то есть нужен своп каналов R и B при каждом копировании.
Решение делается в одной маленькой функции:
|
1 2 3 4 5 |
// Решает, совпадает ли формат пикселей битмапа с нашим TPixel32 (BGRA) function BitmapNeedsRBSwap(ABitmap: FMX.Graphics.TBitmap): Boolean; begin Result := ABitmap.PixelFormat = TPixelFormat.RGBA; end; |
И применяется через внутреннюю процедуру копирования строки:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
// Копирует строку из формата FMX в наш BGRA (или обратно), // при необходимости меняя местами R и B procedure CopyRowSwapIfNeeded(Src, Dst: PByte; PixelCount: Integer; SwapRB: Boolean); var I: Integer; S, D: PCardinal; V: Cardinal; begin if not SwapRB then begin Move(Src^, Dst^, PixelCount * 4); Exit; end; S := PCardinal(Src); D := PCardinal(Dst); for I := 0 to PixelCount - 1 do begin // Делаем свап байтов 0 и 2: AABBGGRR <-> AARRGGBB V := S^; D^ := (V and $FF00FF00) or // AA00GG00 ((V and $00FF0000) shr 16) or // + 00BB(RR)0000 -> 000000BB(RR) ((V and $000000FF) shl 16); // + 000000BB(RR) <- 00BB(RR)0000 Inc(S); Inc(D); end; end; |
На Windows, где формат совпадает, мы делаем один Move на всю строку — быстро и без лишней работы. На платформах с RGBA приходится идти попиксельно со свопом, медленнее, но другого пути нет. Решение принимается один раз на строку, а не на каждый пиксель — if not SwapRB стоит вне цикла.
Сама операция симметрична: что для чтения из битмапа, что для записи в битмап — алгоритм один. R и B меняются местами, G и A остаются на местах. Поэтому одна и та же функция используется и в CopyFromBitmap, и в CopyToBitmap.
CopyFromBitmap
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
procedure TFmxMemorySurface32.CopyFromBitmap(const ABitmap: FMX.Graphics.TBitmap); var BD: TBitmapData; Y: Integer; SrcPtr, DstPtr: PByte; SwapRB: Boolean; begin if ABitmap = nil then raise EArgumentNilException.Create('CopyFromBitmap: ABitmap must not be nil'); SetSize(ABitmap.Width, ABitmap.Height); FAlphaMode := amPremultiplied; // FMX-битмапы всегда premultiplied if (FWidth = 0) or (FHeight = 0) then Exit; SwapRB := BitmapNeedsRBSwap(ABitmap); if ABitmap.Map(TMapAccess.Read, BD) then try for Y := 0 to FHeight - 1 do begin SrcPtr := PByte(BD.GetScanline(Y)); DstPtr := @FData[NativeInt(Y) * FStride]; CopyRowSwapIfNeeded(SrcPtr, DstPtr, FWidth, SwapRB); end; finally ABitmap.Unmap(BD); end else raise EInvalidOperation.Create( 'CopyFromBitmap: failed to Map bitmap for reading'); end; |
Логика прямолинейная: устанавливаем размер, фиксируем amPremultiplied (FMX-битмапы всегда premultiplied — это свойство платформы, не наше предположение), проверяем нулевой размер, и далее построчно копируем через Map/Unmap.
Парное применение Map/Unmap обрамляет только то время, пока мы реально копируем строки. Никаких алгоритмов внутри Map не происходит. Это принципиально — Map короткоживущий ресурс, и мы его держим строго на время копирования. Алгоритм будет работать дальше с уже нашим буфером FData, который никем не залочен.
SetSize(0, 0) корректно отрабатывается базовым классом — буфер FData получит длину 0, и мы выходим, не пытаясь делать Map пустого битмапа.
CopyToBitmap
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
procedure TFmxMemorySurface32.CopyToBitmap(var ABitmap: FMX.Graphics.TBitmap); var BD: TBitmapData; Y: Integer; SrcPtr, DstPtr: PByte; SwapRB: Boolean; begin if ABitmap = nil then ABitmap := FMX.Graphics.TBitmap.Create; if (ABitmap.Width <> FWidth) or (ABitmap.Height <> FHeight) then ABitmap.SetSize(FWidth, FHeight); if (FWidth = 0) or (FHeight = 0) then Exit; SwapRB := BitmapNeedsRBSwap(ABitmap); if ABitmap.Map(TMapAccess.Write, BD) then try for Y := 0 to FHeight - 1 do begin SrcPtr := @FData[NativeInt(Y) * FStride]; DstPtr := PByte(BD.GetScanline(Y)); CopyRowSwapIfNeeded(SrcPtr, DstPtr, FWidth, SwapRB); end; finally ABitmap.Unmap(BD); end else raise EInvalidOperation.Create( 'CopyToBitmap: failed to Map bitmap for writing'); end; |
Зеркальный метод. Параметр var ABitmap означает, что вызывающий может передать nil, и тогда мы создадим битмап сами. Это удобно для разовых случаев, когда результат не нужно складывать в заранее существующий битмап. Если битмап передан, но не того размера — приводим к нужному через SetSize.
SwapRB проверяется именно у целевого битмапа, а не у нашего буфера. Потому что наш буфер всегда BGRA, а вот битмап может оказаться на платформе с RGBA — тогда при записи нужно свопить. Это та же асимметрия, что в CopyFromBitmap, только с обратным знаком.
Что про AlphaMode
Заметьте, что CopyFromBitmap принудительно ставит amPremultiplied. А CopyToBitmap никак не трогает альфа-режим целевого битмапа — потому что в FMX просто нет свойства, аналогичного VCL-овскому AlphaFormat. FMX-битмап всегда premultiplied, выбора нет.
Если пользователь хочет работать в amIgnored (то есть игнорировать альфу при обработке), он может поменять режим у поверхности после CopyFromBitmap. Это будет означать «я знаю, что физически данные premultiplied, но обрабатывать их хочу как непрозрачные».
Итог по FMX
Вся специфика FMX уместилась в:
- одну функцию определения формата (BitmapNeedsRBSwap);
- одну функцию построчного копирования со свопом (CopyRowSwapIfNeeded);
- два метода обмена с битмапом (CopyFromBitmap / CopyToBitmap);
- три конструктора-загрузчика для удобства.
Все остальные требования интерфейса — GetScanLine, GetData, GetWidth, GetHeight, SetSize, SetAlphaMode, размещение пикселей в памяти — обеспечены базовым классом TMemoryImageSurface32. Алгоритм, написанный для IImageSurface32, не имеет ни малейшего понятия, что под ним FMX, что внутри был Map, и что на маке свопались каналы. Он видит ровно тот же интерфейс, что в VCL и LCL.
Если завтра понадобится поддержка, скажем, Skia — мы напишем TSkiaMemorySurface32 ровно по той же схеме: что-то про чтение пикселей, что-то про запись, остальное унаследовано.
Переходим к VCL-реализации. Из-за возможности прямого доступа к буферу пикселей в этой реализации можно развернуться во всю ширь.
Реализация для VCL
VCL-битмап (Vcl.Graphics.TBitmap) — мой главный попутчик по жизни. Большинство приложений на VCL уже работают с TBitmap: загружают, рисуют, показывают на канве. Логично, что наши алгоритмы должны прозрачно работать с этим объектом.
Но «прозрачно» — это не одно и то же в разных сценариях. Иногда у пользователя уже есть заполненный битмап, и копировать пиксели только ради того, чтобы запустить алгоритм — это лишние мегабайты в памяти и лишние миллисекунды на копирование. А иногда наоборот, оригинальный битмап трогать нельзя, нужен независимый рабочий буфер, который алгоритм может изменять как угодно, не затрагивая источник.
Поэтому реализаций для VCL две:
- TVclMemorySurface32 — наследник TMemoryImageSurface32 с собственным буфером, специализированный под VCL. Есть методы CopyFromBitmap / CopyToBitmap для обмена данными с битмапом, но между этими копированиями поверхность живёт независимо.
- TVclBitmapSurface — обёртка вокруг существующего TBitmap без копирования. Все обращения через IImageSurface32 адресуют тот же самый буфер пикселей в DIB битмапа. Изменения через интерфейс мгновенно видны через свойства битмапа, и наоборот.
TVclMemorySurface32: собственный буфер с VCL-раскладкой
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
type // Класс с собственным буфером памяти для пикселей, // реализует IImageSurface32 с мягкой логикой TVclMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; function GetScanLine(Y: Integer): PPixel32Array; override; public // Создаёт поверхность, копируя данные из переданного TBitmap // Внутри конвертирует в pf32bit, если нужно, и копирует данные constructor CreateFromBitmap(const ABitmap: TBitmap); overload; // Копирует содержимое из указанного TBitmap, // конвертирует в pf32bit если надо procedure CopyFromBitmap(const ABitmap: TBitmap); // Копирует данные поверхности обратно в TBitmap, // создаёт или конвертирует bitmap если надо procedure CopyToBitmap(var ABitmap: TBitmap); end; |
Наследуется от TMemoryImageSurface32 и переопределяет, помимо CreateSurface, ещё и GetScanLine:
|
1 2 3 4 5 6 |
function TVclMemorySurface32.GetScanLine(Y: Integer): PPixel32Array; begin CheckRange(Y); // Return pointer to scanline Y, bottom-up storage (Y reversed). Result := PPixel32Array(@FData[NativeInt(FHeight - 1 - Y) * FStride]); end; |
В TMemoryImageSurface32 строка Y — это байты Y*Stride .. (Y+1)*Stride-1 от начала буфера. В TVclMemorySurface32 логическая строка Y хранится физически на месте Height-1-Y. То есть в памяти расклад тот же, что у VCL: первая строка в памяти — нижняя строка картинки.
Зачем это? Чтобы CopyFromBitmap и CopyToBitmap могли копировать одним Move весь блок пикселей, без построчных циклов:
|
1 |
Move(ABitmap.ScanLine[FHeight - 1]^, FData[0], Length(FData)); |
Bitmap.ScanLine[Height-1] — указатель на начало DIB (нижняя строка). FData[0] — начало нашего буфера, тоже соответствует нижней строке. Раскладка совпадает, можно копировать целиком.
Если бы мы не инвертировали GetScanLine, пришлось бы либо копировать построчно (медленнее), либо иметь рассогласование между «логическим» порядком в ScanLine[Y] и физическим порядком в памяти, что усложнило бы и Data, и понимание класса.
Data для TVclMemorySurface32 остаётся унаследованным:
|
1 2 3 4 5 |
// унаследовано от TMemoryImageSurface32: function GetData: Pointer; begin Result := Pointer(FData); end; |
И возвращает он начало физического буфера, что в нашей раскладке соответствует нижней строке картинки.
CopyFromBitmap: копирование с конвертацией формата
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
procedure TVclMemorySurface32.CopyFromBitmap(const ABitmap: TBitmap); var bmp: TBitmap; begin if ABitmap = nil then raise EArgumentNilException.Create ('CopyFromBitmap: ABitmap must not be nil'); // Создаём временный bitmap с pf32bit, если исходник другой формат if ABitmap.PixelFormat <> pf32bit then begin bmp := TBitmap.Create; try bmp.Assign(ABitmap); bmp.PixelFormat := pf32bit; CopyFromBitmap(bmp); Exit; finally bmp.Free; end; end; SetSize(ABitmap.Width, ABitmap.Height); if ABitmap.AlphaFormat = afIgnored then FAlphaMode := amIgnored else FAlphaMode := amPremultiplied; // pf32bit гарантирует плотную упаковку строк, без зазоров, // поэтому мы можем использовать перенос всего массива пикселей Move(ABitmap.ScanLine[FHeight - 1]^, FData[0], Length(FData)); end; |
Логика двухступенчатая. Если формат не pf32bit, то делаем временный битмап, копируем туда исходник через Assign (получаем независимую копию), переводим временный в pf32bit, и рекурсивно вызываем себя на нём. Рекурсия завершается за один шаг, потому что временный битмап уже в нужном формате.
Если формат уже pf32bit, выставляем размер, копируем AlphaMode из AlphaFormat, и одним Move переносим все пиксели. Здесь работает то самое знание про bottom-up: ScanLine[Height-1] — это начало DIB, FData[0] — начало нашего буфера, обе раскладки совпадают.
CopyToBitmap: обратное копирование
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
procedure TVclMemorySurface32.CopyToBitmap(var ABitmap: TBitmap); var bmp: TBitmap; begin // Если битмап не передан, создаём новый нужного формата if ABitmap = nil then begin ABitmap := TBitmap.Create; ABitmap.PixelFormat := pf32bit; if FAlphaMode = amIgnored then ABitmap.AlphaFormat := afIgnored else ABitmap.AlphaFormat := afPremultiplied; ABitmap.SetSize(FWidth, FHeight); end; // Если битмап не в pf32bit или неподходящего размера - создаём новый if (ABitmap.PixelFormat <> pf32bit) or (ABitmap.Width <> FWidth) or (ABitmap.Height <> FHeight) then begin bmp := TBitmap.Create; try bmp.PixelFormat := pf32bit; bmp.SetSize(FWidth, FHeight); CopyToBitmap(bmp); ABitmap.Assign(bmp); Exit; finally bmp.Free; end; end; if FAlphaMode = amIgnored then ABitmap.AlphaFormat := afIgnored else ABitmap.AlphaFormat := afPremultiplied; Move(FData[0], ABitmap.ScanLine[FHeight - 1]^, Length(FData)); end; |
Здесь две ветви для удобства пользователя. Если он передал ABitmap = nil, процедура создаст битмап сама с нужным форматом, размером и альфой, а пользователь получит результат через var-параметр. Если передал битмап неподходящего формата или размера — мы не трогаем его свойства напрямую (PixelFormat := …; SetSize(…)), потому что это сбросило бы атрибуты целевого битмапа. Вместо этого делаем подходящий временный битмап и копируем в него, а потом через Assign приводим целевой к нужному виду. Assign корректно перенесёт пиксельные данные, не разрушая остального.
Если же пришёл битмап правильного формата и размера, копируем напрямую одним Move.
TVclBitmapSurface: обёртка без копирования
Класс короткий по содержанию, но в нём несколько тонкостей, связанных со спецификой VCL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
type // Оборачивает TBitmap как IImageSurface32 без копирования // Требует PixelFormat = pf32bit, иначе бросает исключение TVclBitmapSurface = class(TInterfacedObject, IImageSurface32) private FBitmap: TBitmap; FOwnsBitmap: Boolean; function GetWidth: Integer; function GetHeight: Integer; function GetScanLine(Y: Integer): PPixel32Array; function GetAlphaMode: TAlphaMode; function GetData: Pointer; function CreateSurface: IImageSurface32; procedure SetAlphaMode(const Value: TAlphaMode); procedure SetSize(AWidth, AHeight: Integer); public // Создает обертку вокруг существующего TBitmap // Если AOwnsBitmap = True, переданный Bitmap // будет освобождён при уничтожении constructor Create(ABitmap: TBitmap; AOwnsBitmap: Boolean = False); destructor Destroy; override; // Битмап, вокруг которого построена обёртка property Bitmap: TBitmap read FBitmap; property AlphaMode: TAlphaMode read GetAlphaMode; property Width: Integer read GetWidth; property Height: Integer read GetHeight; end; |
Новый конструктор
|
1 2 3 4 5 6 7 8 9 10 11 |
constructor TVclBitmapSurface.Create(ABitmap: TBitmap; AOwnsBitmap: Boolean = False); begin inherited Create; if ABitmap = nil then raise EArgumentNilException.Create('ABitmap must not be nil'); if ABitmap.PixelFormat <> pf32bit then raise EArgumentException.Create('Bitmap.PixelFormat must be pf32bit'); FBitmap := ABitmap; FOwnsBitmap := AOwnsBitmap; end; |
Конструктор требует уже готовый битмап в формате pf32bit. Это сознательное ограничение: обёртка не должна молча конвертировать формат — это была бы неявная и потенциально дорогая операция. Если у пользователя битмап другого формата, пусть он явно решит, что с этим делать: либо конвертировать самому, либо использовать TVclMemorySurface32.CreateFromBitmap, который для того и сделан.
Параметр AOwnsBitmap — это управление временем жизни. По умолчанию обёртка не владеет битмапом: пользователь передал свой, пользователь и освободит. Но иногда удобно создать битмап специально для оборачивания и забыть про него, тогда AOwnsBitmap = True, и битмап освободится в деструкторе вместе с обёрткой.
|
1 2 3 4 5 6 |
destructor TVclBitmapSurface.Destroy; begin if FOwnsBitmap then FBitmap.Free; inherited; end; |
Этот же приём используется в TVclBitmapSurface.CreateSurface, где создаём временный битмап и сразу передаём владение обёртке.
Bottom-up в VCL и тонкость GetData
Повторюсь, что особенность VCL-битмапа заключается в том, что строки в DIB лежат снизу вверх. То есть ScanLine[0] указывает на верхнюю строку картинки, но физически это последняя строка в памяти. А ScanLine[Height-1] наоборот, нижняя строка картинки, но первая в памяти.
Это влияет на реализацию GetData, который должен возвращать указатель на начало непрерывного блока пикселей в памяти:
|
1 2 3 4 5 6 7 |
function TVclBitmapSurface.GetData: Pointer; begin if FBitmap.Height <= 0 then Result := nil else Result := FBitmap.ScanLine[FBitmap.Height - 1]; end; |
Тут работают сразу два знания о VCL: что строки идут снизу вверх (отсюда Height-1), и что для pf32bit они лежат вплотную без выравнивающих байт (Width × 4 всегда кратно четырём, никакой padding не нужен). Если бы битмап был, например, pf24bit, между строками мог бы быть padding, и Move на весь объём дал бы мусор. Но pf32bit мы обеспечили в конструкторе.
Получается семантическое согласие с TVclMemorySurface32.GetData: оба класса возвращают указатель на «начало непрерывного блока в bottom-up порядке». Алгоритм, использующий Data, видит одну и ту же картину независимо от того, какая из двух VCL-реализаций под ним.
Проверка на Height <= 0 нужна, чтобы для пустого битмапа возвращать nil, а не падать с исключением — как мы и договорились в семантике IImageSurface32.Data.
Тонкость SetAlphaMode на заполненном битмапе
|
1 2 3 4 5 6 7 8 9 |
procedure TVclBitmapSurface.SetAlphaMode(const Value: TAlphaMode); begin if Value = AlphaMode then Exit; if Value = amIgnored then FBitmap.AlphaFormat := afIgnored else FBitmap.AlphaFormat := afPremultiplied; end; |
Внешне просто, но за FBitmap.AlphaFormat := afPremultiplied стоит физический проход по всем пикселям с умножением RGB на A. На пустом битмапе (Width × Height = 0) это ничего не делает; на маленьком — незаметно; на 4К-картинке — заметная пауза.
Поэтому имеет смысл следовать паттерну Create -> SetAlphaMode -> SetSize: установить режим альфы до того, как буфер заполнился чем-то непустым. Тогда SetAlphaMode никаких пикселей не трогает (битмап ещё пустой), а SetSize после неё аллоцирует буфер уже в нужном режиме.
Если же пользователь сначала наполнил битмап, а потом меняет режим — это легально, но он должен понимать, что VCL переберёт все пиксели.
Сохранение AlphaFormat в SetSize
Здесь приятный нюанс VCL. Vcl.Graphics.TBitmap.SetSize сохраняет AlphaFormat при изменении размера, не сбрасывая его в afIgnored. Это сделано как раз для того, чтобы избежать длительных конвертаций при последовательных операциях. Поэтому наш SetSize остаётся одной строкой:
|
1 2 3 4 |
procedure TVclBitmapSurface.SetSize(AWidth, AHeight: Integer); begin FBitmap.SetSize(AWidth, AHeight); end; |
И семантика AlphaMode как «свойства поверхности, переживающего изменение размера» соблюдается бесплатно, за счёт самого VCL.
CreateSurface создаёт чистую обёртку
|
1 2 3 4 5 6 7 8 |
function TVclBitmapSurface.CreateSurface: IImageSurface32; var bmp: TBitmap; begin bmp := TBitmap.Create; bmp.PixelFormat := pf32bit; Result := TVclBitmapSurface.Create(bmp, True); end; |
Создаётся пустой битмап в pf32bit, оборачивается обёрткой с владением. Размер — нулевой, режим альфы — amIgnored (значение по умолчанию для нового TBitmap). Программист дальше выставит то и другое сам по своему сценарию.
Передача AOwnsBitmap = True принципиальна: новая поверхность сама отвечает за созданный для неё битмап. Когда последняя ссылка на интерфейс уйдёт, и поверхность будет уничтожена, битмап освободится автоматически.
Итог по VCL: что выбрать пользователю
Если у пользователя уже есть TBitmap и он не возражает, чтобы алгоритм его модифицировал, выбираем TVclBitmapSurface. Никакого копирования, изменения через интерфейс мгновенно отражаются в битмапе.
Если нужна независимая копия, или исходный битмап имеет формат, отличный от pf32bit, или нужно сначала поработать в буфере, а потом отдать результат в другой битмап, выбираем TVclMemorySurface32.
Обе реализации идентичны для алгоритма, он работает через IImageSurface32 и не отличает одну от другой. Разница только в политике владения данными.
Боевое крещение: Один алгоритм на три экосистемы
У нас всё готово, чтобы наконец убедиться, что мероприятие было затеяно не зря. Возьмём типичную задачу обработки изображений — альфа-блендинг одного битмапа на другой со смещением (X, Y) и общей непрозрачностью AOpacity и реализуем её один раз, через IImageSurface32. А потом из VCL-, FMX- и LCL-проектов вызовем эту функцию, передав ей родные битмапы каждой экосистемы.
Сам алгоритм
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 |
procedure NormalizeForBlend(const ASurface: IImageSurface32); begin // У amIgnored поверхностей в альфе может лежать мусор // SourceOver требует валидной альфы, выставляем 255 // AlphaMode у вызывающего не меняем if ASurface.AlphaMode = amIgnored then FixAlpha(ASurface); end; // Накладывает ASrc на ADst в позицию (ADstX, ADstY) по схеме SourceOver // для premultiplied: dst = src + dst * (1 - src.a) // AOpacity (0..255) — дополнительный множитель альфы источника // Прямоугольник источника клиппируется по границам приёмника function BlendSurface(const ADst, ASrc: IImageSurface32; ADstX, ADstY: Integer; AOpacity: Byte): IImageSurface32; var SX0, SY0, SX1, SY1: Integer; DX0, DY0, W, H, X, Y: Integer; S, D: PPixel32; SP, DP: TPixel32; begin if (ADst = nil) or (ASrc = nil) then raise EArgumentNilException.Create( 'BlendSurface: surfaces must not be nil'); if (ADst.Width = 0) or (ADst.Height = 0) or (ASrc.Width = 0) or (ASrc.Height = 0) then Exit(nil); NormalizeForBlend(ADst); NormalizeForBlend(ASrc); Result := ADst.CreateSurface; Result.AlphaMode := ADst.AlphaMode; Result.SetSize(ADst.Width, ADst.Height); CopyPixels(ADst, Result); if AOpacity = 0 then Exit; // Клиппинг прямоугольника источника по границам приёмника DX0 := ADstX; DY0 := ADstY; SX0 := 0; SY0 := 0; SX1 := ASrc.Width; SY1 := ASrc.Height; if DX0 < 0 then begin Inc(SX0, -DX0); DX0 := 0; end; if DY0 < 0 then begin Inc(SY0, -DY0); DY0 := 0; end; if DX0 + (SX1 - SX0) > ADst.Width then SX1 := SX0 + (ADst.Width - DX0); if DY0 + (SY1 - SY0) > ADst.Height then SY1 := SY0 + (ADst.Height - DY0); W := SX1 - SX0; H := SY1 - SY0; if (W <= 0) or (H <= 0) then Exit; for Y := 0 to H - 1 do begin S := @ASrc.ScanLine[SY0 + Y]^[SX0]; D := @Result.ScanLine[DY0 + Y]^[DX0]; for X := 0 to W - 1 do begin SP := PremultiplyPixel(S, AOpacity); DP := PremultiplyPixel(D, 255 - SP.A); D^ := SP + DP; Inc(S); Inc(D); end; end; end; |
Весь код — это чистая работа с пикселями. В нём нет ни одного упоминания Vcl.Graphics, FMX.Graphics, TLazIntfImage или хотя бы Windows. Алгоритм видит ровно то, что обещает интерфейс: ширину, высоту, scanline-ы и режим альфы.
Несколько ключевых мест.
NormalizeForBlend. Для того, чтобы наложение отработало корректно, надо привести альфу в нормальное состояние. А именно, если поверхность помечена как не предумноженная, необходимо установить альфа-канал в 255, иначе там будет мусор. Если поверхность имеет признак amPremultiplied, верим, что пиксели находятся в предумноженном состоянии и ничего не трогаем.
Result := ADst.CreateSurface — та самая фабрика из интерфейса. Алгоритм не знает, что под ним: если вход был VCL-обёрткой, результат тоже будет VCL-обёрткой; если LCL — будет LCL. Алгоритму это безразлично, он получает «такую же поверхность».
Цикл по строкам через ScanLine[Y] — здесь нам важна согласованность: индекс Y отсчитывается от верха картинки, и обе поверхности (источник и приёмник) интерпретируют его одинаково, независимо от того, как физически лежат строки в памяти. В VCL они идут снизу вверх, в FMX и LCL — сверху вниз; алгоритм об этом ничего не знает и знать не хочет.
Внутренний цикл по пикселям — работа с PPixel32 напрямую через Inc, без обращений к интерфейсу. Виртуальный вызов был один раз на строку (ScanLine[Y]), внутри строки — голый указатель. Это и есть «нулевой оверхед», который мы заявляли в начале.
Вызов из VCL

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
function ActionBlend(ADst, ASrc: TBitmap; X, Y: Integer; AOpacity: Byte): TBitmap; var S, D, R: IImageSurface32; begin Result := nil; S := TVclBitmapSurface.Create(ASrc); D := TVclBitmapSurface.Create(ADst); R := BlendSurface(D, S, X, Y, AOpacity); if Assigned(R) then begin Result := TBitmap.Create; Result.Assign(TVclBitmapSurface(R).Bitmap); end; end; |
В VCL мы используем обёртку без копирования — TVclBitmapSurface. Битмапы остаются на своих местах, обёртка просто даёт алгоритму прямой доступ к их пикселям. После работы BlendSurface возвращает новую поверхность (созданную через CreateSurface приёмника, тоже TVclBitmapSurface, со своим внутренним битмапом), и нам остаётся только достать этот битмап через Assign, чтобы вызывающая сторона получила независимый экземпляр.
Никаких копирований пикселей до и после работы алгоритма не происходит — мы платим только за сам блендинг.
Вызов из FMX

|
1 2 3 4 5 6 7 8 9 10 11 |
function ActionBlend(ADst, ASrc: TBitmap; X, Y: Integer; AOpacity: Byte): TBitmap; var S, D, R: IImageSurface32; begin Result := nil; S := TFmxMemorySurface32.CreateFromBitmap(ASrc); D := TFmxMemorySurface32.CreateFromBitmap(ADst); R := BlendSurface(D, S, X, Y, AOpacity); if Assigned(R) then (R as TFmxMemorySurface32).CopyToBitmap(Result); end; |
В FMX прямого доступа к пикселям нет, Map явление недолговечное. Поэтому работаем через копию: CreateFromBitmap забирает пиксели через Map/Unmap в свой буфер, при необходимости свопая каналы R и B. AlphaMode выставляется автоматически в amPremultiplied, потому что FMX-битмапы всегда такие.
После работы CopyToBitmap возвращает результат в новый FMX.Graphics.TBitmap, снова через Map. Сам алгоритм между этими двумя точками работает с обычной памятью на скорости, не отличающейся от VCL-варианта. Дополнительное время уходит на предварительное копирование данных и обратное копирование.
Так как могу проверить на Андроиде, добавил текущий формат пикселя и операционную систему:

Как видим, время увеличилось — формат пикселя RGBA и нам надо два раза полностью пробегать по битмапу, с целью изменить порядок следования R и B. Но даже с учётом этого, подобный пробег по таким немаленьким битмапам 1315 x 877 и 480 x 457 уложился в 23 миллисекунды — это очень хороший результат.
Вызов из LCL

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
function ActionBlend(ADst, ASrc: TBitmap; X, Y: Integer; AOpacity: Byte): TBitmap; var S, D, R: IImageSurface32; begin Result := nil; S := TLclMemorySurface32.CreateFromBitmap(ASrc); S.AlphaMode := amPremultiplied; D := TLclMemorySurface32.CreateFromBitmap(ADst); D.AlphaMode := amPremultiplied; R := BlendSurface(D, S, X, Y, AOpacity); if Assigned(R) then (R as TLclMemorySurface32).CopyToBitmap(Result); end; |
В LCL та же схема, что и в FMX — копирование через TLazIntfImage с гарантированно заданным форматом Init_BPP32_B8G8R8A8_BIO_TTB. Разница в одной детали: CreateFromBitmap в LCL ставит amIgnored, потому что у LCL нет надёжного способа узнать, premultiplied ли данные в битмапе. Но мы точно знаем, что наши PNG уже в premultiplied — поэтому явно выставляем amPremultiplied после загрузки. Это сценарий «пользователь знает лучше системы», о котором говорилось в разделе про LCL.
Краткие итоги
Три проекта, три экосистемы и одна и та же функция BlendSurface, одна на всех. Различия трёх ActionBlend сводятся к одному: какую реализацию IImageSurface32 создать на входе и как достать результат на выходе. Это всё.
Если завтра я оптимизирую BlendSurface через SIMD, или добавлю режим overlay вместо normal, или поменяю порядок обхода для лучшей локальности кэша, изменения тут же отразятся во всех трёх экосистемах. Без копипасты и без портирования.
Это и есть то, ради чего затевался интерфейс.
Цепочки обработки
Один алгоритм — это хорошо, но интересное начинается, когда их становится несколько. Вот тут единый интерфейс начинает приносить совсем другой уровень удобства.
Равномерное осветление поверхности
Напишем простейшую операцию — равномерное осветление поверхности:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
// Возвращает копию ASrc, в которой каждый пиксель равномерно осветлён // на AAmount. Альфа-канал сохраняется; смещаются только RGB-компоненты // в сторону белого. AAmount = 0 даёт неизменённую копию, AAmount = 255 - // полностью белое изображение (с исходной альфой). // // Параметры: // ASrc - исходная поверхность; не должна быть nil. // AAmount - величина осветления, 0..255. function Lighten(const ASrc: IImageSurface32; AAmount: Byte): IImageSurface32; var I, Total: Integer; S, D: PPixel32; begin if ASrc = nil then raise EArgumentNilException.Create( 'Lighten: surface must not be nil'); if (ASrc.Width = 0) or (ASrc.Height = 0) then Exit(nil); Result := ASrc.CreateSurface; Result.AlphaMode := ASrc.AlphaMode; Result.SetSize(ASrc.Width, ASrc.Height); if AAmount = 0 then begin CopyPixels(ASrc, Result); Exit; end; // Порядок строк не важен - идём через Data // одним сплошным проходом Total := ASrc.Width * ASrc.Height; S := PPixel32(ASrc.Data); D := PPixel32(Result.Data); for I := 0 to Total - 1 do begin D^ := S^.Lighter(AAmount); Inc(S); Inc(D); end; end; |
Здесь, кстати, наконец-то использован прямой доступ через Data — тот самый Pattern 1, обещанный в разделе про интерфейс. Когда порядок обхода нам безразличен (а в попиксельных операциях вроде осветления — именно так), нет смысла дёргать ScanLine[Y] в цикле. Берём указатель на начало всей пиксельной памяти и идём по ней одним сплошным проходом. Ни одного виртуального вызова на всю функцию.
Теперь самое интересное — цепочка:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
function ActionLightenAndBlend(ADst, ASrc: TBitmap; X, Y: Integer; AOpacity, ALighten: Byte): TBitmap; var S, D, R: IImageSurface32; begin Result := nil; S := TVclBitmapSurface.Create(ASrc); D := TVclBitmapSurface.Create(ADst); // Сначала осветляем фон, потом накладываем источник. R := BlendSurface(Lighten(D, ALighten), S, X, Y, AOpacity); if Assigned(R) then begin Result := TBitmap.Create; Result.Assign(TVclBitmapSurface(R).Bitmap); end; end; |
Что тут интересного. BlendSurface не отличает, что ей передали — оригинальный битмап, обёрнутый в TVclBitmapSurface, или результат Lighten. Для неё это одинаковые IImageSurface32. Каждый шаг возвращает поверхность, готовую быть аргументом следующего. Промежуточные результаты не превращаются в TBitmap и обратно — пиксели просто текут через цепочку, оставаясь всё это время в одном и том же BGRA32. А так как работаем с интерфейсами, они корректно уничтожаться при покидании зоны видимости.

Второй момент: код выше написан для VCL, но Lighten от этого фреймворконезависим ровно так же, как BlendSurface. В исходниках в конце статьи аналогичный вызов сделан и для FMX / LCL.
Градиентное осветление
Равномерно осветлять весь фон, это рабочий вариант, но скучный. В реальном проекте у меня лежит чуть более амбициозная функция — LighterGradient. Она делает примерно то же самое, но не равномерно, а по градиенту: горизонтальному, вертикальному, диагональному или радиальному, с инверсией и заданным диапазоном силы осветления.
Кода в ней под сотню строк — каждое направление обрабатывается отдельной веткой, плюс предвычисление массивов градиентов, плюс отдельная история для радиального (с подсчётом расстояния до центра). Полный разбор тянет на самостоятельную статью, поэтому здесь я её только покажу в действии. По своей сути она ничем не отличается от предыдущего осветления — IImageSurface32 на входе, IImageSurface32 на выходе, встаёт в цепочку как родная:
|
1 2 3 |
R := BlendSurface( LighterGradient(D, AMode, not AInvert, 0, AOpacity), S, X, Y, AOpacity); |
А вот как это выглядит на экране — демка из VCL-проекта:

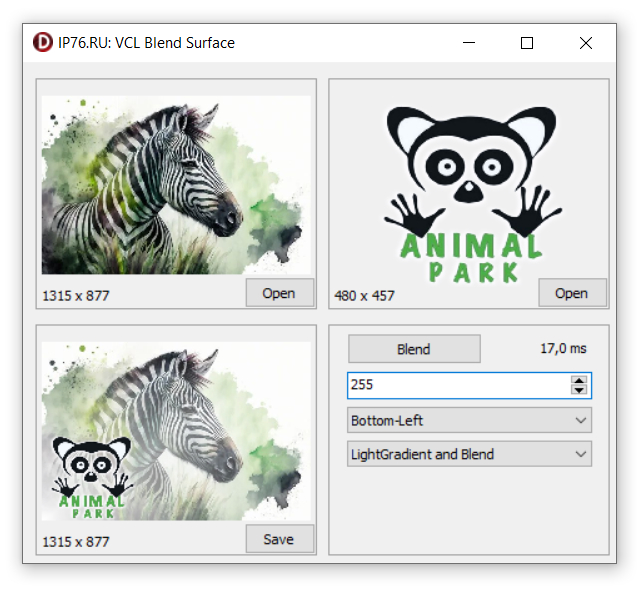
Сверху — два исходных изображения: фотореалистичная зебра-акварель (1315 x 877) и логотип «Animal Park» с прозрачным фоном (480 x 457). Снизу слева — результат: логотип наложен на фон, который перед этим был осветлён градиентом «Bottom-Left» (то есть сильнее всего в левом нижнем углу). 17 миллисекунд на всю цепочку для картинки 1315 x 877.
Нижним CombBox’ом можно выбрать режим смешивания. Можно поменять направление, поиграть с opacity. Под капотом каждый раз — одна и та же цепочка BlendSurface(LighterGradient(…), …) или BlendSurface(Lighten(…), …), и эта цепочка вызывает строго фреймворконезависимые функции.
Для сравнения, как бы это выглядело без градиентного осветления:

Скриншот сделан на VCL, но точно такая же демка собирается на FMX и LCL с тем же визуальным результатом. Что, собственно, и требовалось доказать.
Заключение
Мы спроектировали и реализовали тонкую прослойку между алгоритмами обработки изображений и графическими фреймворками. Получился один интерфейс IImageSurface32 на полусотни строк, базовая реализация TMemoryImageSurface32 и четыре фреймворковые реализации — две для VCL (с владением и без), по одной для FMX и LCL. Разделение по модулям не косметика, а необходимость. Каждый фреймворковый модуль тянет за собой свой набор unit-ов (Vcl.Graphics, FMX.Graphics, IntfGraphics) и в один файл их сводить ну вот совсем не нужно: один проект может физически не иметь доступа к юнитам другого фреймворка. Зато базовый модуль не зависит вообще ни от чего, кроме SysUtils и Math. Алгоритмы, которые на нём будут написаны, наследуют эту чистоту.
При этом каждый из четырёх модулей действительно читается за чашку кофе. Без внешних библиотек, без иерархий классов, без обвязки.
В качестве доказательства жизнеспособности конструкции мы написали полноценный альфа-блендинг с клиппингом, premultiplied-композитингом и общей непрозрачностью, плюс пару операций для построения цепочек. Одна функция — три рабочих экосистемы. Прикладной код, который её вызывает, занимает 5–10 строк и сводится к двум действиям: «оберни битмап» и «достань результат». Всё остальное внутри интерфейса.
Цена этой универсальности оказалась символической. Виртуальный вызов один раз на строку при использовании ScanLine[Y], ноль вызовов при попиксельной работе через Data. Для алгоритмов, которые крутят миллионы пикселей во внутренних циклах, такой оверхед лежит ниже погрешности измерения. Зато выигрыш ощутимый: математика отвязана от фреймворка навсегда. Можно писать алгоритм один раз и переиспользовать его в любом проекте на Delphi или Lazarus, какой бы графический стек он ни использовал.
И главное — интерфейс получился действительно минимальным. Не «архитектурно красивым», не «расширяемым на все случаи жизни», а ровно таким, какой нужен алгоритмам: указатель на пиксели, ширина строки в байтах, размеры, режим альфы. Всё. Если завтра понадобится поддержка Skia, GDI+, или какой-нибудь нативной поверхности iOS — добавится ещё один класс по тому же шаблону: пара методов обмена с битмапом, остальное унаследовано. Без переписывания алгоритмов.
Планы
Этот интерфейс — фундамент, на котором имеет смысл строить дальше. Планирую изучить, сделать и, если получится, описать:
- Ресамплинг. Масштабирование изображений: bilinear, bicubic, Lanczos. Два последних пока знаю только в теории, руками ещё не делал. Но очень интересно было бы сделать.
- Блюр. Возвращение к серии о размытии, но уже без привязки к Vcl.Graphics.TBitmap. Те же алгоритмы — от гауссовой свёртки до box blur со скользящей суммой и треугольного ядра.
- Пиксельные эффекты и градиенты. Осветление, затемнение, инверсия, цветовые матрицы, градиентные маски. Простые по математике, но дающие огромный визуальный выхлоп в комбинации с блендингом и блюром.
Интерфейс, который мы построили сегодня, даёт возможность сосредоточиться исключительно на математике, не отвлекаясь на то, чей TBitmap сейчас используется.
API интерфейса ещё не финализирован. По мере добавления блюров, ресамплинга и эффектов он может уточняться. Например, уже сейчас просится метод Clone. Когда API устаканится, исходники будут выложены в публичный репозиторий, ссылка появится в этой и других статьях серии.
Листинги
Тут представлены полные исходники модулей. Можно копировать как есть, зависимостей нет — только стандартные unit-ы. Также, всё можно скачать одним архивом в конце статьи.
Базовый модуль: IP76.Imaging.Surface
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 |
//****************************************************************************** // Project: IP76.RU // Created: 2026-05 // // Description: Core BGRA pixel and surface types, premultiply and // alpha utilities // Описание: Базовые типы пикселя и поверхности BGRA, // premultiply и работа с альфой // Article: https://ip76.ru/image-surface/ //****************************************************************************** unit IP76.Imaging.Surface; {$IFDEF FPC} {$MODE DELPHI} {$ENDIF} interface uses {$IFNDEF FPC}System.SysUtils{$ELSE}SysUtils{$ENDIF}; type // Внутренний формат пикселя // Жёстко фиксирован на 32-битный BGRA TPixel32 = packed record B: Byte; G: Byte; R: Byte; A: Byte; class operator Equal(const A, B: TPixel32) : Boolean; class operator NotEqual(const A, B: TPixel32): Boolean; class operator Add(const A, B: TPixel32): TPixel32; class function Zero: TPixel32; static; function Invert: TPixel32; function InvertPremul: TPixel32; function Lighter(Value: Byte): TPixel32; function LighterPremul(Value: Byte): TPixel32; function Darker(Value: Byte): TPixel32; end; PPixel32 = ^TPixel32; TPixel32Array = array[0..0] of TPixel32; PPixel32Array = ^TPixel32Array; // Кэш ScanLine - чтобы не вызывать ScanLine[Y] повторно TScanLineCache = array of PPixel32Array; // Интерпретация альфа-канала TAlphaMode = ( amIgnored, // альфа не участвует в алгоритмах amPremultiplied // цвета предумножены на альфу ); // Поверхность 32-битных BGRA пикселей IImageSurface32 = interface ['{0FB211FD-B255-43BB-90EB-95312DD40C40}'] function GetWidth: Integer; function GetHeight: Integer; function GetScanLine(Y: Integer): PPixel32Array; function GetAlphaMode: TAlphaMode; function GetData: Pointer; procedure SetAlphaMode(const Value: TAlphaMode); // Установить размеры procedure SetSize(AWidth, AHeight: Integer); // Создать новый экземпляр function CreateSurface: IImageSurface32; property Width: Integer read GetWidth; property Height: Integer read GetHeight; // Начало массива пикселей: // Возвращает указатель на начало непрерывного блока // пикселей в памяти, откуда можно последовательно // читать всю поверхность по пикселям. // Порядок строк (например, bottom-up или top-down) - // не фиксируется и зависит от реализации. property Data: Pointer read GetData; // Строка по индексу Y, отсчёт от верха property ScanLine[Y: Integer]: PPixel32Array read GetScanLine; default; // Текущий альфа-режим property AlphaMode: TAlphaMode read GetAlphaMode write SetAlphaMode; end; // Реализация в памяти TMemoryImageSurface32 = class(TInterfacedObject, IImageSurface32) strict protected FWidth: Integer; FHeight: Integer; FStride: Integer; // = FWidth * SizeOf(TPixel32), кэш для GetScanLine FData: TBytes; FAlphaMode: TAlphaMode; function GetWidth: Integer; inline; function GetHeight: Integer; inline; function GetAlphaMode: TAlphaMode; inline; procedure SetAlphaMode(const Value: TAlphaMode); inline; function GetData: Pointer; inline; procedure CheckRange(Y: Cardinal); inline; // Virtual block function GetScanLine(Y: Integer): PPixel32Array; virtual; function CreateSurface: IImageSurface32; virtual; public constructor Create; overload; constructor Create(AWidth, AHeight: Integer); overload; procedure SetSize(AWidth, AHeight: Integer); property Width: Integer read GetWidth; property Height: Integer read GetHeight; property AlphaMode: TAlphaMode read GetAlphaMode write SetAlphaMode; property Data: Pointer read GetData; property ScanLine[Y: Integer]: PPixel32Array read GetScanLine; default; end; {$Region 'Utils'} // Проверяет, содержит ли битмап осмысленный альфа-канал // (есть и прозрачные, и непрозрачные пиксели, или полупрозрачные). function CheckBitmapAlpha(const ABitmap: IImageSurface32): Boolean; // Устанавливает все значения альфы в 255 (полностью непрозрачный). function FixAlpha(ABitmap: IImageSurface32): Boolean; // Строит кэш указателей ScanLine для быстрого доступа к строкам. function BuildScanLineCache(Bitmap: IImageSurface32): TScanLineCache; overload; function BuildScanLineCache(W, H: Integer): TScanLineCache; overload; procedure ClearScanLineCache(const ACache: TScanLineCache; W, H: Integer); // Ограничивает Value диапазоном [MinVal..MaxVal] function Clamp(Value, MinVal, MaxVal: Integer): Integer; {$EndRegion} {$Region 'Premultiply'} // Premultiply: копирует пиксели из Src в Dst с умножением каналов // на альфу через LUT. // Один проход: копирование + преобразование. // Src и Dst должны быть pf32bit одинакового размера. function PremultiplyPixel(const S: PPixel32; AOpacity: Byte): TPixel32; procedure PremultiplyPixels(const Src, Dst: IImageSurface32); // Unpremultiply: копирует пиксели из Src в Dst с обратным // преобразованием через LUT. // Один проход: копирование + преобразование. // Src и Dst должны быть pf32bit одинакового размера. procedure UnpremultiplyPixels(const Src, Dst: IImageSurface32); // Копирует пиксели из Src в Dst, устанавливая альфу в 255. // Один проход: копирование + исправление альфы. // Src и Dst должны быть pf32bit одинакового размера. procedure CopyFixAlphaPixels(const Src, Dst: IImageSurface32); // Unpremultiply + установка альфы в 255 за один проход. // Src и Dst должны быть pf32bit одинакового размера. procedure UnpremultiplyFixAlphaPixels(const Src, Dst: IImageSurface32); // Копирование пикселей без преобразований. // Src и Dst должны быть pf32bit одинакового размера. procedure CopyPixels(const Src, Dst: IImageSurface32); {$EndRegion} implementation uses {$IFNDEF FPC}System.Math{$ELSE}Math{$ENDIF}; {$Region 'Utils'} function CheckBitmapAlpha(const ABitmap: IImageSurface32): Boolean; var I, Total: Integer; P: PPixel32; HasTransparent, HasOpaque: Boolean; begin if not (Assigned(ABitmap)) then exit(False); Total := ABitmap.Width * ABitmap.Height; if Total = 0 then exit(False); P := ABitmap.Data; HasTransparent := False; HasOpaque := False; for I := 0 to Total - 1 do begin if (P^.A > 0) and (P^.A < 255) then exit(True); if P^.A = 0 then begin if HasOpaque then exit(True); HasTransparent := True; end else if P^.A = 255 then begin if HasTransparent then exit(True); HasOpaque := True; end; Inc(P); end; Result := False; end; function FixAlpha(ABitmap: IImageSurface32): Boolean; var I, Total: Integer; P: PPixel32; begin if not (Assigned(ABitmap)) then exit(False); Total := ABitmap.Width * ABitmap.Height; if Total = 0 then exit(False); P := ABitmap.Data; for I := 0 to Total - 1 do begin P^.A := 255; Inc(P); end; Result := True; end; function BuildScanLineCache(Bitmap: IImageSurface32): TScanLineCache; overload; var Y: Integer; begin SetLength(Result, Bitmap.Height); for Y := 0 to Bitmap.Height - 1 do Result[Y] := Bitmap.ScanLine[Y]; end; function BuildScanLineCache(W, H: Integer): TScanLineCache; overload; var Y, S: Integer; begin SetLength(Result, H); S := W * SizeOf(TPixel32); for Y := 0 to H - 1 do Result[Y] := AllocMem(S); end; procedure ClearScanLineCache(const ACache:TScanLineCache; W, H: Integer); var Y, S: Integer; begin S := W * SizeOf(TPixel32); for Y := 0 to H - 1 do FreeMem(ACache[Y], S); end; function Clamp(Value, MinVal, MaxVal: Integer): Integer; begin if Value < MinVal then Result := MinVal else if Value > MaxVal then Result := MaxVal else Result := Value; end; {$EndRegion} {$Region 'Premultiply LUT'} var // [Value, Alpha] = Value * Alpha / 255 (rounded) PremulTable: array[0..255, 0..255] of Byte; // [Value, Alpha] = Value * 255 / Alpha (rounded, clamped) UnpremulTable: array[0..255, 0..255] of Byte; procedure InitPremulTables; var V, A: Integer; begin for V := 0 to 255 do for A := 0 to 255 do begin PremulTable[V, A] := (V * A + 127) div 255; if A > 0 then UnpremulTable[V, A] := Min(255, (V * 255 + A div 2) div A) else UnpremulTable[V, A] := 0; end; end; function PremultiplyPixel(const S: PPixel32; AOpacity: Byte): TPixel32; var A: Byte; begin A := AOpacity; if A = 255 then Result := S^ else if A = 0 then Result := TPixel32.Zero else begin Result.B := PremulTable[S^.B, A]; Result.G := PremulTable[S^.G, A]; Result.R := PremulTable[S^.R, A]; Result.A := PremulTable[S^.A, A]; end; end; procedure PremultiplyPixels(const Src, Dst: IImageSurface32); var I, Total: Integer; S, D: PPixel32; A: Byte; begin Total := Src.Width * Src.Height; if Total = 0 then exit; S := Src.Data; D := Dst.Data; for I := 0 to Total - 1 do begin A := S^.A; if A = 255 then D^ := S^ else if A = 0 then begin D^.B := 0; D^.G := 0; D^.R := 0; D^.A := 0; end else begin D^.B := PremulTable[S^.B, A]; D^.G := PremulTable[S^.G, A]; D^.R := PremulTable[S^.R, A]; D^.A := A; end; Inc(S); Inc(D); end; end; procedure UnpremultiplyPixels(const Src, Dst: IImageSurface32); var I, Total: Integer; S, D: PPixel32; A: Byte; begin Total := Src.Width * Src.Height; if Total = 0 then exit; S := Src.Data; D := Dst.Data; for I := 0 to Total - 1 do begin A := S^.A; if A = 255 then D^ := S^ else if A = 0 then begin D^.B := 0; D^.G := 0; D^.R := 0; D^.A := 0; end else begin D^.B := UnpremulTable[S^.B, A]; D^.G := UnpremulTable[S^.G, A]; D^.R := UnpremulTable[S^.R, A]; D^.A := A; end; Inc(S); Inc(D); end; end; procedure CopyFixAlphaPixels(const Src, Dst: IImageSurface32); var I, Total: Integer; S, D: PPixel32; begin Total := Src.Width * Src.Height; if Total = 0 then exit; S := Src.Data; D := Dst.Data; for I := 0 to Total - 1 do begin D^ := S^; D^.A := 255; Inc(S); Inc(D); end; end; procedure UnpremultiplyFixAlphaPixels(const Src, Dst: IImageSurface32); var I, Total: Integer; S, D: PPixel32; A: Byte; begin Total := Src.Width * Src.Height; if Total = 0 then exit; S := Src.Data; D := Dst.Data; for I := 0 to Total - 1 do begin A := S^.A; if A = 255 then D^ := S^ else if A = 0 then begin D^.B := 0; D^.G := 0; D^.R := 0; D^.A := 255; end else begin D^.B := UnpremulTable[S^.B, A]; D^.G := UnpremulTable[S^.G, A]; D^.R := UnpremulTable[S^.R, A]; D^.A := 255; end; Inc(S); Inc(D); end; end; procedure CopyPixels(const Src, Dst: IImageSurface32); var S, D: PByte; Total: Integer; begin Total := Src.Width * Src.Height * SizeOf(TPixel32); if Total = 0 then Exit; S := Src.Data; D := Dst.Data; Move(S^, D^, Total); end; {$EndRegion} {$Region 'TPixel32'} class operator TPixel32.Equal(const A, B: TPixel32) : Boolean; begin Result := (A.B = B.B) and (A.G = B.G) and (A.R = B.R) and (A.A = B.A); end; class operator TPixel32.NotEqual(const A, B: TPixel32): Boolean; begin Result := (A.B <> B.B) or (A.G <> B.G) or (A.R <> B.R) or (A.A <> B.A); end; class operator TPixel32.Add(const A, B: TPixel32): TPixel32; begin Result.B := A.B + B.B; Result.G := A.G + B.G; Result.R := A.R + B.R; Result.A := A.A + B.A; end; const ZeroPixel32: TPixel32 = (B:0; G:0; R:0; A:0); class function TPixel32.Zero: TPixel32; begin Result := ZeroPixel32; end; function TPixel32.Invert: TPixel32; begin Result.B := 255 - B; Result.G := 255 - G; Result.R := 255 - R; Result.A := A; end; function TPixel32.InvertPremul: TPixel32; begin Result.B := A - B; Result.G := A - G; Result.R := A - R; Result.A := A; end; function TPixel32.Lighter(Value: Byte): TPixel32; begin Result.B := B + PremulTable[(255 - B), Value] ; Result.G := G + PremulTable[(255 - G), Value]; Result.R := R + PremulTable[(255 - R), Value]; Result.A := A; end; function TPixel32.LighterPremul(Value: Byte): TPixel32; begin Result.B := B + PremulTable[(A - B), Value] ; Result.G := G + PremulTable[(A - G), Value]; Result.R := R + PremulTable[(A - R), Value]; Result.A := A; end; function TPixel32.Darker(Value: Byte): TPixel32; begin Result.B := B - PremulTable[B, Value] ; Result.G := G - PremulTable[G, Value]; Result.R := R - PremulTable[R, Value]; Result.A := A; end; {$EndRegion} {$Region 'TMemoryImageSurface32'} { TMemoryImageSurface32 } constructor TMemoryImageSurface32.Create; begin inherited Create; FAlphaMode := amIgnored; end; constructor TMemoryImageSurface32.Create(AWidth, AHeight: Integer); begin Create; // делегируем, там будет вызов inherited SetSize(AWidth, AHeight); end; procedure TMemoryImageSurface32.SetSize(AWidth, AHeight: Integer); var ByteCount: NativeInt; begin if (AWidth < 0) or (AHeight < 0) then raise EArgumentException.Create('SetSize: Dimensions cannot be negative'); FWidth := AWidth; FHeight := AHeight; FStride := FWidth * SizeOf(TPixel32); ByteCount := NativeInt(FHeight) * NativeInt(FStride); if (FHeight <> 0) and (ByteCount div NativeInt(FHeight) <> NativeInt(FStride)) then raise EIntOverflow.Create('SetSize: buffer size overflow'); SetLength(FData, ByteCount); end; function TMemoryImageSurface32.GetWidth: Integer; begin Result := FWidth; end; function TMemoryImageSurface32.GetHeight: Integer; begin Result := FHeight; end; function TMemoryImageSurface32.GetAlphaMode: TAlphaMode; begin Result := FAlphaMode; end; procedure TMemoryImageSurface32.SetAlphaMode(const Value: TAlphaMode); begin FAlphaMode := Value; end; procedure TMemoryImageSurface32.CheckRange(Y: Cardinal); begin if Y >= Cardinal(FHeight) then raise ERangeError.CreateFmt('ScanLine index out of range: %d', [Y]); end; function TMemoryImageSurface32.GetScanLine(Y: Integer): PPixel32Array; begin CheckRange(Cardinal(Y)); Result := PPixel32Array(@FData[NativeInt(Y) * FStride]); end; function TMemoryImageSurface32.GetData: Pointer; begin Result := Pointer(FData) end; function TMemoryImageSurface32.CreateSurface: IImageSurface32; begin Result := TMemoryImageSurface32.Create; end; {$EndRegion} initialization InitPremulTables; end. |
Реализация VCL: IP76.Imaging.Surface.Vcl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 |
//****************************************************************************** // Project: IP76.RU // Created: 2026-05 // // Description: VCL TBitmap adapters - IImageSurface32 wrapper, // memory surface, file save // Описание: Адаптеры VCL TBitmap - обёртка IImageSurface32, // поверхность в памяти, сохранение // Article: https://ip76.ru/image-surface/ //****************************************************************************** unit IP76.Imaging.Surface.Vcl; interface uses System.SysUtils, Vcl.Graphics, IP76.Imaging.Surface; type // Оборачивает TBitmap как IImageSurface32 без копирования // Требует PixelFormat = pf32bit, иначе бросает исключение TVclBitmapSurface = class(TInterfacedObject, IImageSurface32) private FBitmap: TBitmap; FOwnsBitmap: Boolean; function GetWidth: Integer; function GetHeight: Integer; function GetScanLine(Y: Integer): PPixel32Array; function GetAlphaMode: TAlphaMode; function GetData: Pointer; function CreateSurface: IImageSurface32; procedure SetAlphaMode(const Value: TAlphaMode); procedure SetSize(AWidth, AHeight: Integer); public // Создает обертку вокруг существующего TBitmap // Если AOwnsBitmap = True, переданный Bitmap // будет освобождён при уничтожении constructor Create(ABitmap: TBitmap; AOwnsBitmap: Boolean = False); destructor Destroy; override; // Битмап, вокруг которого построена обёртка property Bitmap: TBitmap read FBitmap; property AlphaMode: TAlphaMode read GetAlphaMode; property Width: Integer read GetWidth; property Height: Integer read GetHeight; end; // Класс с собственным буфером памяти для пикселей, // реализует IImageSurface32 с мягкой логикой TVclMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; function GetScanLine(Y: Integer): PPixel32Array; override; public // Создаёт поверхность, копируя данные из переданного TBitmap // Внутри конвертирует в pf32bit, если нужно, и копирует данные constructor CreateFromBitmap(const ABitmap: TBitmap); overload; // Копирует содержимое из указанного TBitmap, // конвертирует в pf32bit если надо procedure CopyFromBitmap(const ABitmap: TBitmap); // Копирует данные поверхности обратно в TBitmap, // создаёт или конвертирует bitmap если надо procedure CopyToBitmap(var ABitmap: TBitmap); end; // Сохранить битмап в файл. Формат определяется по расширению procedure SaveBitmapAs(Bitmap: TBitmap; const FileName: string); implementation procedure SaveBitmapAs(Bitmap: TBitmap; const FileName: string); var WIC: TWICImage; S: string; begin WIC := TWICImage.Create; try WIC.Assign(Bitmap); S := ExtractFileExt(FileName).ToLower; if S='.png' then WIC.ImageFormat := wifPng else if (S='.jpg') or (S='.jpeg') then WIC.ImageFormat := wifJpeg else if S='.gif' then WIC.ImageFormat := wifGif else if S='.tiff' then WIC.ImageFormat := wifTiff else if S='.bmp' then WIC.ImageFormat := wifBmp else if (S='.wdp') or (S='.hdp') then WIC.ImageFormat := wifWMPhoto else raise EArgumentException.CreateFmt( 'SaveBitmapAs: unsupported file extension "%s"', [S]); WIC.SaveToFile(FileName); finally WIC.Free; end; end; {TVclBitmapSurface } constructor TVclBitmapSurface.Create(ABitmap: TBitmap; AOwnsBitmap: Boolean); begin inherited Create; if ABitmap = nil then raise EArgumentNilException.Create('ABitmap must not be nil'); if ABitmap.PixelFormat <> pf32bit then raise EArgumentException.Create('Bitmap.PixelFormat must be pf32bit'); FBitmap := ABitmap; FOwnsBitmap := AOwnsBitmap; end; destructor TVclBitmapSurface.Destroy; begin if FOwnsBitmap then FBitmap.Free; inherited; end; function TVclBitmapSurface.GetWidth: Integer; begin Result := FBitmap.Width; end; function TVclBitmapSurface.GetHeight: Integer; begin Result := FBitmap.Height; end; function TVclBitmapSurface.GetAlphaMode: TAlphaMode; begin if FBitmap.AlphaFormat = afIgnored then Result := amIgnored else Result := amPremultiplied; end; function TVclBitmapSurface.GetData: Pointer; begin if FBitmap.Height <= 0 then Result := nil else Result := FBitmap.ScanLine[FBitmap.Height - 1]; end; function TVclBitmapSurface.CreateSurface: IImageSurface32; var bmp: TBitmap; begin bmp := TBitmap.Create; bmp.PixelFormat := pf32bit; Result := TVclBitmapSurface.Create(bmp, True); end; procedure TVclBitmapSurface.SetAlphaMode(const Value: TAlphaMode); begin if Value = AlphaMode then Exit; if Value = amIgnored then FBitmap.AlphaFormat := afIgnored else FBitmap.AlphaFormat := afPremultiplied; end; procedure TVclBitmapSurface.SetSize(AWidth, AHeight: Integer); begin FBitmap.SetSize(AWidth, AHeight); end; function TVclBitmapSurface.GetScanLine(Y: Integer): PPixel32Array; begin if Cardinal(Y) >= Cardinal(FBitmap.Height) then raise ERangeError.CreateFmt('ScanLine index out of range: %d', [Y]); Result := PPixel32Array(FBitmap.ScanLine[Y]); end; { TVclMemorySurface32 } constructor TVclMemorySurface32.CreateFromBitmap(const ABitmap: TBitmap); begin inherited Create; CopyFromBitmap(ABitmap); end; function TVclMemorySurface32.CreateSurface: IImageSurface32; begin Result := TVclMemorySurface32.Create; end; function TVclMemorySurface32.GetScanLine(Y: Integer): PPixel32Array; begin CheckRange(Cardinal(Y)); Result := PPixel32Array(@FData[NativeInt(FHeight - 1 - Y) * FStride]); end; procedure TVclMemorySurface32.CopyFromBitmap(const ABitmap: TBitmap); var bmp: TBitmap; begin if ABitmap = nil then raise EArgumentNilException.Create ('CopyFromBitmap: ABitmap must not be nil'); // Создаём временный bitmap с pf32bit, если исходник другой формат if ABitmap.PixelFormat <> pf32bit then begin bmp := TBitmap.Create; try bmp.Assign(ABitmap); bmp.PixelFormat := pf32bit; CopyFromBitmap(bmp); Exit; finally bmp.Free; end; end; SetSize(ABitmap.Width, ABitmap.Height); if ABitmap.AlphaFormat = afIgnored then FAlphaMode := amIgnored else FAlphaMode := amPremultiplied; // pf32bit гарантирует плотную упаковку строк, без зазоров, // поэтому мы можем использовать перенос всего массива пикселей Move(ABitmap.ScanLine[FHeight - 1]^, FData[0], Length(FData)); end; procedure TVclMemorySurface32.CopyToBitmap(var ABitmap: TBitmap); var bmp: TBitmap; begin // Если битмап не передан, создаём новый нужного формата if ABitmap = nil then begin ABitmap := TBitmap.Create; ABitmap.PixelFormat := pf32bit; if FAlphaMode = amIgnored then ABitmap.AlphaFormat := afIgnored else ABitmap.AlphaFormat := afPremultiplied; ABitmap.SetSize(FWidth, FHeight); end; // Если битмап не в pf32bit или неподходящего размера - создаём новый if (ABitmap.PixelFormat <> pf32bit) or (ABitmap.Width <> FWidth) or (ABitmap.Height <> FHeight) then begin bmp := TBitmap.Create; try bmp.PixelFormat := pf32bit; bmp.SetSize(FWidth, FHeight); CopyToBitmap(bmp); ABitmap.Assign(bmp); Exit; finally bmp.Free; end; end; if FAlphaMode = amIgnored then ABitmap.AlphaFormat := afIgnored else ABitmap.AlphaFormat := afPremultiplied; Move(FData[0], ABitmap.ScanLine[FHeight - 1]^, Length(FData)); end; end. |
Реализация FMX: IP76.Imaging.Surface.Fmx
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 |
//****************************************************************************** // Project: IP76.RU // Created: 2026-05 // // Description: FMX TBitmap adapter - // memory surface with file/stream loaders (BGRA/RGBA aware) // Описание: Адаптер FMX TBitmap - // поверхность с загрузкой из файла/потока (BGRA/RGBA) // Article: https://ip76.ru/image-surface/ //****************************************************************************** unit IP76.Imaging.Surface.Fmx; interface uses System.SysUtils, System.Classes, FMX.Graphics, FMX.Types, IP76.Imaging.Surface; type // Поверхность в памяти с копированием в/из FMX TBitmap TFmxMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; public constructor CreateFromBitmap(const ABitmap: FMX.Graphics.TBitmap); constructor CreateFromFile(const AFileName: string); constructor CreateFromStream(AStream: TStream); procedure CopyFromBitmap(const ABitmap: FMX.Graphics.TBitmap); procedure CopyFromFile(const AFileName: string); procedure CopyFromStream(AStream: TStream); procedure CopyToBitmap(var ABitmap: FMX.Graphics.TBitmap); end; // Загружает файл изображения в 32-битный FMX TBitmap // FMX TBitmap всегда 32-битный (BGRA/RGBA), // отдельная установка PixelFormat не нужна // Имя "32" в названии функции — для единообразия // с другими модулями серии (VCL/LCL) // Возвращает новый TBitmap, владение — у вызывающего function LoadBitmap32FromFile(const AFileName: string): FMX.Graphics.TBitmap; function LoadBitmap32FromStream(AStream: TStream): FMX.Graphics.TBitmap; implementation uses System.Math; {$Region 'Pixel format helpers'} // Копирует строку из формата FMX в наш BGRA (или обратно), // при необходимости меняя местами R и B procedure CopyRowSwapIfNeeded(Src, Dst: PByte; PixelCount: Integer; SwapRB: Boolean); var I: Integer; S, D: PCardinal; V: Cardinal; begin if not SwapRB then begin Move(Src^, Dst^, PixelCount * 4); Exit; end; S := PCardinal(Src); D := PCardinal(Dst); for I := 0 to PixelCount - 1 do begin // Делаем свап байтов 0 и 2: AABBGGRR <-> AARRGGBB V := S^; D^ := (V and $FF00FF00) or // AA00GG00 ((V and $00FF0000) shr 16) or // + 00BB(RR)0000 -> 000000BB(RR) ((V and $000000FF) shl 16); // + 000000BB(RR) <- 00BB(RR)0000 Inc(S); Inc(D); end; end; // Решает, совпадает ли формат пикселей битмапа с нашим TPixel32 (BGRA) function BitmapNeedsRBSwap(ABitmap: FMX.Graphics.TBitmap): Boolean; inline; begin // На Windows FMX использует pf_B8G8R8A8 — свап не нужен // На iOS/macOS/Android FMX использует pf_R8G8B8A8 — свап нужен Result := ABitmap.PixelFormat = TPixelFormat.RGBA; end; {$EndRegion} {$Region 'Loaders'} function LoadBitmap32FromFile(const AFileName: string): FMX.Graphics.TBitmap; begin Result := FMX.Graphics.TBitmap.Create; try Result.LoadFromFile(AFileName); except Result.Free; raise; end; end; function LoadBitmap32FromStream(AStream: TStream): FMX.Graphics.TBitmap; begin Result := FMX.Graphics.TBitmap.Create; try Result.LoadFromStream(AStream); except Result.Free; raise; end; end; {$EndRegion} {$Region 'TFmxMemorySurface32'} function TFmxMemorySurface32.CreateSurface: IImageSurface32; begin Result := TFmxMemorySurface32.Create; end; constructor TFmxMemorySurface32.CreateFromBitmap( const ABitmap: FMX.Graphics.TBitmap); begin inherited Create; CopyFromBitmap(ABitmap); end; constructor TFmxMemorySurface32.CreateFromFile(const AFileName: string); begin inherited Create; CopyFromFile(AFileName); end; constructor TFmxMemorySurface32.CreateFromStream(AStream: TStream); begin inherited Create; CopyFromStream(AStream); end; procedure TFmxMemorySurface32.CopyFromBitmap( const ABitmap: FMX.Graphics.TBitmap); var BD: TBitmapData; Y: Integer; SrcPtr, DstPtr: PByte; SwapRB: Boolean; begin if ABitmap = nil then raise EArgumentNilException.Create( 'CopyFromBitmap: ABitmap must not be nil'); SetSize(ABitmap.Width, ABitmap.Height); // FMX-битмапы всегда premultiplied FAlphaMode := amPremultiplied; if (FWidth = 0) or (FHeight = 0) then Exit; SwapRB := BitmapNeedsRBSwap(ABitmap); if ABitmap.Map(TMapAccess.Read, BD) then try for Y := 0 to FHeight - 1 do begin SrcPtr := PByte(BD.GetScanline(Y)); DstPtr := @FData[NativeInt(Y) * FStride]; CopyRowSwapIfNeeded(SrcPtr, DstPtr, FWidth, SwapRB); end; finally ABitmap.Unmap(BD); end else raise EInvalidOperation.Create( 'CopyFromBitmap: failed to Map bitmap for reading'); end; procedure TFmxMemorySurface32.CopyFromFile(const AFileName: string); var Bmp: FMX.Graphics.TBitmap; begin Bmp := LoadBitmap32FromFile(AFileName); try CopyFromBitmap(Bmp); finally Bmp.Free; end; end; procedure TFmxMemorySurface32.CopyFromStream(AStream: TStream); var Bmp: FMX.Graphics.TBitmap; begin Bmp := LoadBitmap32FromStream(AStream); try CopyFromBitmap(Bmp); finally Bmp.Free; end; end; procedure TFmxMemorySurface32.CopyToBitmap(var ABitmap: FMX.Graphics.TBitmap); var BD: TBitmapData; Y: Integer; SrcPtr, DstPtr: PByte; SwapRB: Boolean; begin if ABitmap = nil then ABitmap := FMX.Graphics.TBitmap.Create; if (ABitmap.Width <> FWidth) or (ABitmap.Height <> FHeight) then ABitmap.SetSize(FWidth, FHeight); if (FWidth = 0) or (FHeight = 0) then Exit; SwapRB := BitmapNeedsRBSwap(ABitmap); if ABitmap.Map(TMapAccess.Write, BD) then try for Y := 0 to FHeight - 1 do begin SrcPtr := @FData[NativeInt(Y) * FStride]; DstPtr := PByte(BD.GetScanline(Y)); CopyRowSwapIfNeeded(SrcPtr, DstPtr, FWidth, SwapRB); end; finally ABitmap.Unmap(BD); end else raise EInvalidOperation.Create( 'CopyToBitmap: failed to Map bitmap for writing'); end; {$EndRegion} end. |
Реализация LCL: IP76.Imaging.Surface.Lcl
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 |
//****************************************************************************** // Project: IP76.RU // Created: 2026-05 // // Description: LCL TBitmap/TGraphic adapter - // memory surface via TLazIntfImage // Описание: Адаптер LCL TBitmap/TGraphic - // поверхность в памяти через TLazIntfImage // Article: https://ip76.ru/image-surface/ //****************************************************************************** unit IP76.Imaging.Surface.Lcl; {$MODE DELPHI} interface uses SysUtils, Classes, Graphics, GraphType, IntfGraphics, FPImage, LCLType, IP76.Imaging.Surface; type // Поверхность в памяти с копированием в/из TBitmap TLclMemorySurface32 = class(TMemoryImageSurface32) strict protected function CreateSurface: IImageSurface32; override; public constructor CreateFromBitmap(const ABitmap: TBitmap); constructor CreateFromGraphic(AGraphic: TGraphic); procedure CopyFromBitmap(const ABitmap: TBitmap); procedure CopyFromGraphic(AGraphic: TGraphic); procedure CopyToBitmap(var ABitmap: TBitmap); end; // Материализует произвольный TGraphic (PNG/JPEG/BMP/...) // в 32-битный TBitmap с валидным читаемым handle. // Возвращает новый TBitmap, владение — у вызывающего function GraphicToBitmap32(AGraphic: TGraphic): TBitmap; implementation function GraphicToBitmap32(AGraphic: TGraphic): TBitmap; begin Result := TBitmap.Create; Result.PixelFormat := pf32bit; try if (AGraphic = nil) or (AGraphic.Width = 0) or (AGraphic.Height = 0) then Exit; Result.SetSize(AGraphic.Width, AGraphic.Height); // Canvas.Draw надёжно растрирует любой TGraphic в наш 32-битный битмап, // в отличие от Assign, который для PNG/JPEG может оставить handle "пустым" Result.Canvas.Draw(0, 0, AGraphic); except FreeAndNil(Result); raise; end; end; { TLclMemorySurface32 } function TLclMemorySurface32.CreateSurface: IImageSurface32; begin Result := TLclMemorySurface32.Create; end; constructor TLclMemorySurface32.CreateFromBitmap(const ABitmap: TBitmap); begin inherited Create; CopyFromBitmap(ABitmap); end; constructor TLclMemorySurface32.CreateFromGraphic(AGraphic: TGraphic); begin inherited Create; CopyFromGraphic(AGraphic); end; procedure TLclMemorySurface32.CopyFromBitmap( const ABitmap: TBitmap); var IntfImg: TLazIntfImage; Desc: TRawImageDescription; Y: Integer; SrcPtr, DstPtr: PByte; RowSize: Integer; begin if ABitmap = nil then raise EArgumentNilException.Create( 'CopyFromBitmap: ABitmap must not be nil'); Desc.Init_BPP32_B8G8R8A8_BIO_TTB(ABitmap.Width, ABitmap.Height); IntfImg := TLazIntfImage.Create(0, 0); try IntfImg.DataDescription := Desc; IntfImg.LoadFromBitmap(ABitmap.Handle, ABitmap.MaskHandle); SetSize(IntfImg.Width, IntfImg.Height); // LCL TBitmap не различает straight/premultiplied alpha, // поэтому принимаем как amIgnored. Если нужна premultiplied, // пользователь должен вызвать PremultiplyPixels вручную FAlphaMode := amIgnored; RowSize := FWidth * SizeOf(TPixel32); for Y := 0 to FHeight - 1 do begin SrcPtr := PByte(IntfImg.GetDataLineStart(Y)); DstPtr := @FData[NativeInt(Y) * FStride]; Move(SrcPtr^, DstPtr^, RowSize); end; finally IntfImg.Free; end; end; procedure TLclMemorySurface32.CopyFromGraphic(AGraphic: TGraphic); var Tmp: TBitmap; begin Tmp := GraphicToBitmap32(AGraphic); try CopyFromBitmap(Tmp); finally Tmp.Free; end; end; procedure TLclMemorySurface32.CopyToBitmap(var ABitmap: TBitmap); var IntfImg: TLazIntfImage; Desc: TRawImageDescription; Y: Integer; SrcPtr, DstPtr: PByte; RowSize: Integer; ImgH, MskH: HBITMAP; begin if ABitmap = nil then ABitmap := TBitmap.Create; ABitmap.PixelFormat := pf32bit; ABitmap.SetSize(FWidth, FHeight); Desc.Init_BPP32_B8G8R8A8_BIO_TTB(FWidth, FHeight); IntfImg := TLazIntfImage.Create(0, 0); try IntfImg.DataDescription := Desc; IntfImg.SetSize(FWidth, FHeight); RowSize := FWidth * SizeOf(TPixel32); for Y := 0 to FHeight - 1 do begin SrcPtr := @FData[NativeInt(Y) * FStride]; DstPtr := PByte(IntfImg.GetDataLineStart(Y)); Move(SrcPtr^, DstPtr^, RowSize); end; IntfImg.CreateBitmaps(ImgH, MskH, False); ABitmap.Handle := ImgH; ABitmap.MaskHandle := MskH; finally IntfImg.Free; end; end; end. |
Скачать

Демо-проекты:
- Исходники (VCL, FMX, LCL) 5.96 Мб.
- VCL Исходники (zip) 2.08 Мб. Delphi XE 7, Delphi 13.0
- FMX Исходники (zip) 1.95 Мб. Delphi XE 7
- LCL Исходники (zip) 1.94 Мб. Lazarus 4.6
Только IP76.Surface:
- Исходник IP76.Surface (zip) 14.1 Кб.
Исполняемые файлы:
- LCL Исполняемый файл (zip) 2.36 Мб. Built in Lazarus 4.6
- FMX Исполняемый файл (zip) 4.03 Мб. Built in Delphi XE 7
- VCL Исполняемый файл x64 (zip) 2.96 Мб. Built in Delphi 13.0